406 lines
15 KiB
Markdown
406 lines
15 KiB
Markdown
|
|
---
|
|||
|
|
marp: true
|
|||
|
|
paginate: true
|
|||
|
|
author: Laurent Fainsin
|
|||
|
|
math: katex
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
<style>
|
|||
|
|
section::after {
|
|||
|
|
/*custom pagination*/
|
|||
|
|
content: attr(data-marpit-pagination) ' / ' attr(data-marpit-pagination-total);
|
|||
|
|
}
|
|||
|
|
</style>
|
|||
|
|
|
|||
|
|
# Whisper
|
|||
|
|
|
|||
|
|
<u style="text-decoration-color:yellow;">Robust</u> <u style="text-decoration-color:red;">Speech Recognition</u> via <u style="text-decoration-color:green;">Large-Scale</u> <u style="text-decoration-color:blue;">Weak Supervision</u>
|
|||
|
|
|
|||
|
|
<footer>
|
|||
|
|
|
|||
|
|
**W**eb-scale **S**upervised **P**retraining for **S**peech **R**ecognition.
|
|||
|
|
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever.
|
|||
|
|
OpenAI, San Francisco. September 2022. [arXiv:2212.04356](https://arxiv.org/abs/2212.04356).
|
|||
|
|
|
|||
|
|
</footer>
|
|||
|
|
|
|||
|
|
<!--
|
|||
|
|
|
|||
|
|
abstract:
|
|||
|
|
|
|||
|
|
Speech Recognition: speech processing systems trained simply to predict large amounts of transcripts.
|
|||
|
|
|
|||
|
|
Robust: Models generalize well to standard benchmarks and are often competitive with prior fully supervised results. But also multilingual and multitask.
|
|||
|
|
|
|||
|
|
Large-Scale: 680,000 hours audio taken from internet. 1,550M parameters for largest model.
|
|||
|
|
|
|||
|
|
Weak Supervision: Datasets of mixed human and machine-generated data
|
|||
|
|
|
|||
|
|
-->
|
|||
|
|
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
<header>
|
|||
|
|
|
|||
|
|
# Context
|
|||
|
|
|
|||
|
|
</header>
|
|||
|
|
|
|||
|
|
- The trend is toward unsupervised learning (Wav2Vec 2.0, 1M hours of training data) $\rightarrow$ good audio encoders but fine-tuning required.
|
|||
|
|
- Pre-training on multiple supervised datasets and domains improves speech recognition robustness and generalization.
|
|||
|
|
- Limited availability of labeled data in speech recognition, current datasets like [SpeechStew](https://arxiv.org/abs/2104.02133) only totals 5,140 hours of supervision.
|
|||
|
|
- Recent efforts to create larger datasets for speech recognition by relaxing the requirement of gold-standard human-validated transcripts.
|
|||
|
|
- Trade-off between quality and quantity, similar to computer vision where larger weakly supervised datasets significantly improve model robustness and generalization.
|
|||
|
|
|
|||
|
|
<!--
|
|||
|
|
|
|||
|
|
- Baevski et al. (2020)
|
|||
|
|
- Narayanan et al. (2018), Likhomanenko et al. (2020), and Chan et al. (2021)
|
|||
|
|
- SpeechStew: AMI, Broadcast News, Common Voice, LibriSpeech, Switchboard/Fisher, Tedlium, and Wall Street Journal. Chan et al., (2021)
|
|||
|
|
- Chen et al. (2021) and Galvez et al. (2021)
|
|||
|
|
- Russakovsky et al. (2015)
|
|||
|
|
|
|||
|
|
-->
|
|||
|
|
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
<header>
|
|||
|
|
|
|||
|
|
# Dataset & Data Processing
|
|||
|
|
|
|||
|
|
</header>
|
|||
|
|
|
|||
|
|
- Broad distribution of audio from many different environments, recording setups, speakers, and languages, salvaged from the internet.
|
|||
|
|
- Audio language detector and heuristics to detect and filter bad/duplicate transcriptions.
|
|||
|
|
- New dataset: 680,000 hours of weakly labeled audio data, including 117,000 hours of audio for 96 other languages and 125,000 hours of english translation data.
|
|||
|
|
|
|||
|
|
<!--
|
|||
|
|
|
|||
|
|
Pas que de l'anglais contrairement à wave2vec ?
|
|||
|
|
-> Joint multilingual and multitask training with sufficiently large models shows no drawback and even benefits.
|
|||
|
|
|
|||
|
|
An all-uppercase or all-lowercase transcript is very unlikely to be human generated.
|
|||
|
|
This inspection showed a large amount of only partially transcribed or poorly aligned/misaligned transcripts as well as remaining low-quality machine-generated captions that filtering heuristics did not detect.
|
|||
|
|
|
|||
|
|
65% English Speech Recognition (438,218 hours)
|
|||
|
|
18% Translation (125,739 hours)
|
|||
|
|
17% Multilingual Speech Recognition (117,113 hours)
|
|||
|
|
|
|||
|
|
pre-treatement:
|
|||
|
|
- Break audio files 30-second segments paired with subset transcript
|
|||
|
|
- Transcript is Standardization using various rules
|
|||
|
|
1. Remove any phrases between matching brackets ([, ]).
|
|||
|
|
2. Remove any phrases between matching parentheses ((, )).
|
|||
|
|
3. Remove any of the following words: hmm, mm, mhm, mmm, uh, um
|
|||
|
|
4. Remove whitespace characters that comes before an apostrophe ’
|
|||
|
|
5. Convert standard or informal contracted forms of English into the original form.
|
|||
|
|
6. Remove commas (,) between digits
|
|||
|
|
7. Remove periods (.) not followed by numbers
|
|||
|
|
8. Remove symbols as well as diacritics from the text, where symbols are the characters with the Unicode category starting with M, S, or P, except period, percent, and currency symbols that may be detected in the next step.
|
|||
|
|
9. Detect any numeric expressions of numbers and currencies and replace with a form using Arabic numbers, e.g. “Ten thousand dollars” → “$10000”.
|
|||
|
|
10. Convert British spellings into American spellings.
|
|||
|
|
11. Remove remaining symbols that are not part of any numeric expressions.
|
|||
|
|
12. Replace any successive whitespace characters with a space.
|
|||
|
|
- Audio is re-sampled to 16,000 Hz
|
|||
|
|
- 80-channel logmagnitude Mel spectrogram representation computed
|
|||
|
|
- 25-millisecond windows with a stride of 10 milliseconds
|
|||
|
|
- For feature normalization
|
|||
|
|
- we globally scale the input to be between -1 and 1
|
|||
|
|
- with approximately zero mean across the pre-training dataset
|
|||
|
|
- Train on all audio, including segments where there is no speech (though with sub-sampled probability)
|
|||
|
|
|
|||
|
|
-->
|
|||
|
|
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
<header>
|
|||
|
|
|
|||
|
|
# Model
|
|||
|
|
|
|||
|
|
</header>
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
<!--
|
|||
|
|
|
|||
|
|
encoder-decoder Transformer architecture
|
|||
|
|
|
|||
|
|
- Small stem: 2xConv1D (width=3, 2nd Conv1D stride=2) + GELU activation
|
|||
|
|
- Sinusoidal position embeddings
|
|||
|
|
- Encoder Block (Sparse Transformer): MultiHeadAttention -> MLP + residual connections
|
|||
|
|
- Encoder final layer normalization applied
|
|||
|
|
- Decoder: MultiHeadAttention -> Cross attention (from encoder) -> MLP + residual connections
|
|||
|
|
|
|||
|
|
-->
|
|||
|
|
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
<header>
|
|||
|
|
|
|||
|
|
# [GELU](https://paperswithcode.com/method/gelu)
|
|||
|
|
|
|||
|
|
</header>
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
<footer>
|
|||
|
|
|
|||
|
|
$\displaystyle \text{GELU}(x) = x P(X \leq x) = x\Phi(x) = x \frac12 \left[ 1 + \text{erf} \left( x / \sqrt2 \right) \right]$
|
|||
|
|
$X \rightarrow \mathcal{N}(0, 1)$
|
|||
|
|
|
|||
|
|
</footer>
|
|||
|
|
|
|||
|
|
<!--
|
|||
|
|
|
|||
|
|
phi: standard Gaussian cumulative distribution function
|
|||
|
|
erf: Gauss error function, https://en.wikipedia.org/wiki/Error_function
|
|||
|
|
|
|||
|
|
-->
|
|||
|
|
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
<header>
|
|||
|
|
|
|||
|
|
# Sinusoidal position embeddings
|
|||
|
|
|
|||
|
|
</header>
|
|||
|
|
|
|||
|
|
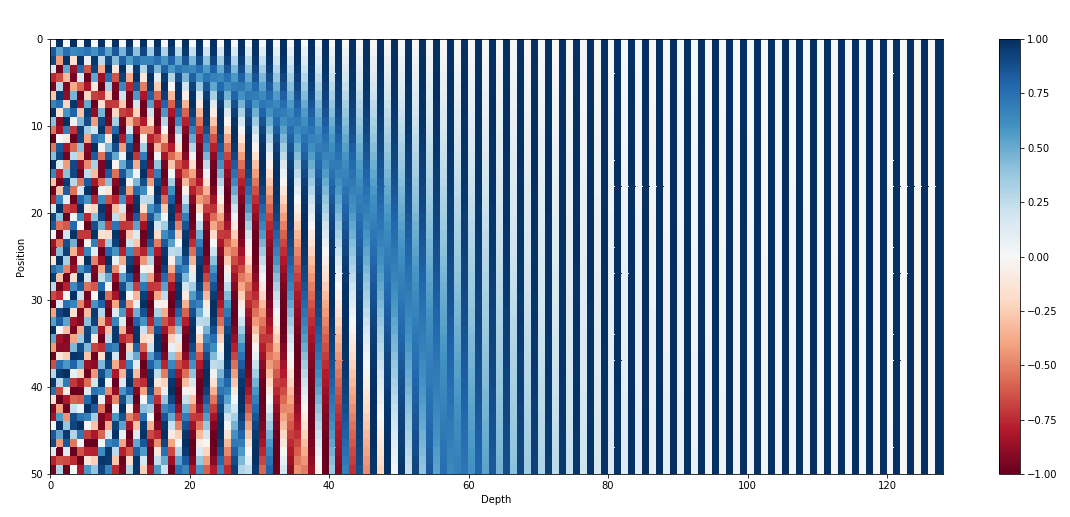
|
|||
|
|
|
|||
|
|
<footer>
|
|||
|
|
|
|||
|
|
$\displaystyle f(t)^{(i)} = \left\{ \begin{array}{l} sin(wk.t), \quad\text{if} i=2k \\ cos(wk.t), \quad\text{if} i=2k+1 \end{array}\right. \quad w_k = \frac{1}{10000^{2k/d}}$
|
|||
|
|
|
|||
|
|
</footer>
|
|||
|
|
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
<header>
|
|||
|
|
|
|||
|
|
# [Sparse <br> Transformer](https://openai.com/blog/sparse-transformer/)
|
|||
|
|
|
|||
|
|
</header>
|
|||
|
|
|
|||
|
|
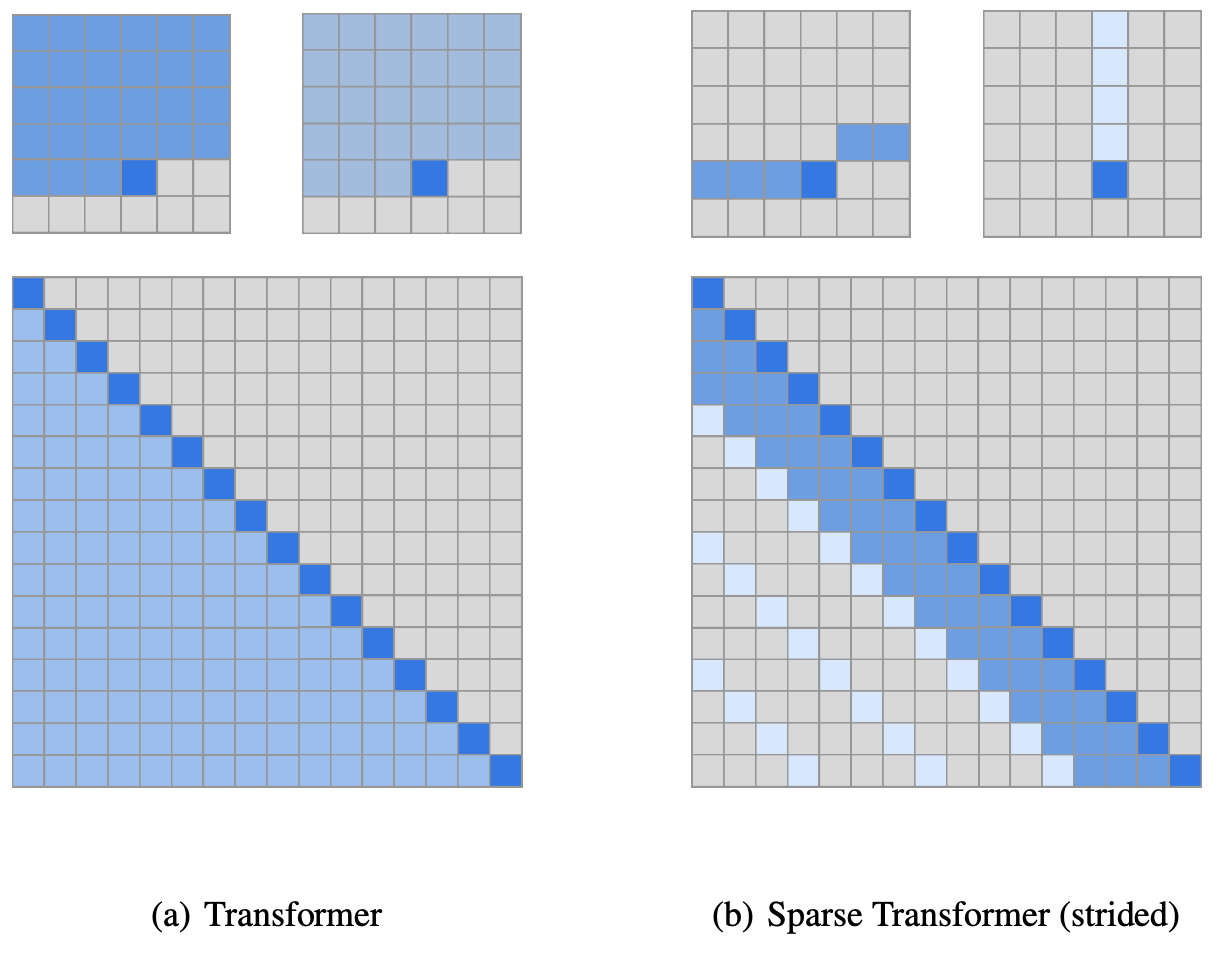
|
|||
|
|
|
|||
|
|
<!-- We’ve developed the Sparse Transformer, a deep neural network which sets new records at predicting what comes next in a sequence—whether text, images, or sound. It uses an algorithmic improvement of the attention mechanism to extract patterns from sequences 30x longer than possible previously. -->
|
|||
|
|
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
<header>
|
|||
|
|
|
|||
|
|
# Multitask
|
|||
|
|
|
|||
|
|
</header>
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
<!--
|
|||
|
|
|
|||
|
|
We use the same byte-level BPE text tokenizer used in GPT2: GPT2TokenizerFast
|
|||
|
|
resized to be multilangual, originally english only
|
|||
|
|
https://github.com/openai/whisper/blob/main/whisper/tokenizer.py#L130
|
|||
|
|
|
|||
|
|
-->
|
|||
|
|
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
<style scoped>
|
|||
|
|
table {
|
|||
|
|
line-height: 0.92rem;
|
|||
|
|
overflow: hidden;
|
|||
|
|
}
|
|||
|
|
</style>
|
|||
|
|
|
|||
|
|
<header>
|
|||
|
|
|
|||
|
|
# Training
|
|||
|
|
|
|||
|
|
</header>
|
|||
|
|
|
|||
|
|
| Hyperparameter | Value |
|
|||
|
|
| :-------------------------------- | :----------: |
|
|||
|
|
| Updates | 1048576 |
|
|||
|
|
| Batch Size | 256 |
|
|||
|
|
| Warmup Updates | 2048 |
|
|||
|
|
| Max grad norm | 1.0 |
|
|||
|
|
| Optimizer | AdamW |
|
|||
|
|
| β1 | 0.9 |
|
|||
|
|
| β2 | 0.98 |
|
|||
|
|
| ε | 10−6 |
|
|||
|
|
| Weight Decay | 0.1 |
|
|||
|
|
| Weight Init Gaussian | Fan-In |
|
|||
|
|
| Learning Rate Schedule | Linear Decay |
|
|||
|
|
| Speechless audio subsample factor | 10× |
|
|||
|
|
| Condition on prior text rate | 50% |
|
|||
|
|
|
|||
|
|
<!--
|
|||
|
|
|
|||
|
|
Zero-shot
|
|||
|
|
|
|||
|
|
between two and three passes over the dataset. Due to only training for a few epochs, over-fitting is not a large concern, and we do not use any data augmentation or regularization.
|
|||
|
|
|
|||
|
|
We used the cross entropy loss over the tokens, similar to language modeling.
|
|||
|
|
|
|||
|
|
Speech recognition research typically evaluates and compares systems based on the word error rate (WER) metric. However, WER, which is based on string edit distance, penalizes all differences between the model’s output and the reference transcript including innocuous differences in transcript style. As a result, systems that output transcripts that would be judged as correct by humans can still have a large WER due to minor formatting differences.
|
|||
|
|
|
|||
|
|
-->
|
|||
|
|
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
<header>
|
|||
|
|
|
|||
|
|
# WER metric
|
|||
|
|
|
|||
|
|
</header>
|
|||
|
|
|
|||
|
|
$$\text{WER} = \frac{S + D + I}{N} = \frac{S + D + I}{S + D + C}$$
|
|||
|
|
|
|||
|
|
$S$ is the number of substitutions
|
|||
|
|
$D$ is the number of deletions
|
|||
|
|
$I$ is the number of insertions
|
|||
|
|
$C$ is the number of correct words
|
|||
|
|
$N$ is the number of words in the reference
|
|||
|
|
|
|||
|
|
$(N=S+D+C)$
|
|||
|
|
|
|||
|
|
<!-- Word error rate (WER) is a common metric of the performance of an automatic speech recognition (ASR) system.
|
|||
|
|
|
|||
|
|
The general difficulty of measuring the performance of ASR systems lies in the fact that the recognized word sequence can have a different length from the reference word sequence (supposedly the correct one). The WER is derived from the Levenshtein distance, working at the word level.
|
|||
|
|
|
|||
|
|
This problem is solved by first aligning the recognized word sequence with the reference (spoken) word sequence using dynamic string alignment. Examination of this issue is seen through a theory called the power law that states the correlation between perplexity and word error rate (see this article for further information).
|
|||
|
|
|
|||
|
|
Word error rate can then be computed as: -->
|
|||
|
|
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
<style scoped>
|
|||
|
|
table {
|
|||
|
|
line-height: 0.77rem;
|
|||
|
|
overflow: hidden;
|
|||
|
|
}
|
|||
|
|
section {
|
|||
|
|
padding: 0;
|
|||
|
|
padding-left: 1rem;
|
|||
|
|
padding-top: 1rem;
|
|||
|
|
}
|
|||
|
|
</style>
|
|||
|
|
|
|||
|
|
<header>
|
|||
|
|
|
|||
|
|
# Evaluation
|
|||
|
|
|
|||
|
|
</header>
|
|||
|
|
|
|||
|
|
| Dataset | wav2vec 2.0 <br> Large (no LM) | Whisper <br> Large V2 | RER <br> (%) |
|
|||
|
|
| :---------------- | :----------------------------: | :-------------------: | :-------------------------------------: |
|
|||
|
|
| LibriSpeech Clean | **2.7** | **2.7** | 0.0 |
|
|||
|
|
| Artie | 24.5 | **6.2** | <span style="color: green;">74.7</span> |
|
|||
|
|
| Common Voice | 29.9 | **9.0** | <span style="color: green;">69.9</span> |
|
|||
|
|
| Fleurs En | 14.6 | **4.4** | <span style="color: green;">69.9</span> |
|
|||
|
|
| Tedlium | 10.5 | **4.0** | <span style="color: green;">61.9</span> |
|
|||
|
|
| CHiME6 | 65.8 | **25.5** | <span style="color: green;">61.2</span> |
|
|||
|
|
| VoxPopuli En | 17.9 | **7.3** | <span style="color: green;">59.2</span> |
|
|||
|
|
| CORAAL | 35.6 | **16.2** | <span style="color: green;">54.5</span> |
|
|||
|
|
| AMI IHM | 37.0 | **16.9** | <span style="color: green;">54.3</span> |
|
|||
|
|
| Switchboard | 28.3 | **13.8** | <span style="color: green;">51.2</span> |
|
|||
|
|
| CallHome | 34.8 | **17.6** | <span style="color: green;">49.4</span> |
|
|||
|
|
| WSJ | 7.7 | **3.9** | <span style="color: green;">49.4</span> |
|
|||
|
|
| AMI SDM1 | 67.6 | **36.4** | <span style="color: green;">46.2</span> |
|
|||
|
|
| LibriSpeech Other | 6.2 | **5.2** | <span style="color: green;">16.1</span> |
|
|||
|
|
| Average | 29.3 | **12.8** | <span style="color: green;">55.2</span> |
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
<!--
|
|||
|
|
|
|||
|
|
commencer par le graph de droite !
|
|||
|
|
|
|||
|
|
zero shot
|
|||
|
|
|
|||
|
|
LibriSpeech as the reference dataset due to its central role in modern speech recognition research and the availability of many released models trained on it, which allows for characterizing robustness behaviors.
|
|||
|
|
|
|||
|
|
-->
|
|||
|
|
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
<header>
|
|||
|
|
|
|||
|
|
# Robustness to noise
|
|||
|
|
|
|||
|
|
</header>
|
|||
|
|
|
|||
|
|

|
|||
|
|

|
|||
|
|
|
|||
|
|
<!-- We tested the noise robustness of Whisper models and 14 LibriSpeech-trained models by measuring the WER when either white noise or pub noise from the Audio Degradation Toolbox (Mauch & Ewert, 2013) was added to the audio. -->
|
|||
|
|
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
<header>
|
|||
|
|
|
|||
|
|
# Human comparison & improvements
|
|||
|
|
|
|||
|
|
</header>
|
|||
|
|
|
|||
|
|

|
|||
|
|

|
|||
|
|
|
|||
|
|
<!-- On most datasets, our text normalizer has similar effect on reducing WERs between Whisper models and other open-source models, compared to FairSpeech’s normalizer. For each dataset, the boxplot shows the distribution of relative WER reduction across different models in our eval suite, showing that using our text normalizer generally results in lower WERs than FairSpeech’s. On a few datasets our normalizer reduces WER significantly and more so for Whisper models, such as CallHome and Switchboard which have many contractions in the ground truth and WSJ which contains many numerical expressions. -->
|
|||
|
|
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
<header>
|
|||
|
|
|
|||
|
|
# Model Scaling
|
|||
|
|
|
|||
|
|
</header>
|
|||
|
|
|
|||
|
|
| Model | Layers | Width | Heads | Parameters | Required VRAM | Relative speed |
|
|||
|
|
| :----- | :----: | :---: | :---: | :--------: | :-----------: | :------------: |
|
|||
|
|
| Tiny | 4 | 384 | 6 | 39M | ~1 GB | ~32x |
|
|||
|
|
| Base | 6 | 512 | 8 | 74M | ~1 GB | ~16x |
|
|||
|
|
| Small | 12 | 768 | 12 | 244M | ~2 GB | ~6x |
|
|||
|
|
| Medium | 24 | 1024 | 16 | 769M | ~5 GB | ~2x |
|
|||
|
|
| Large | 32 | 1280 | 20 | 1550M | ~10 GB | 1x |
|
|||
|
|
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
<header>
|
|||
|
|
|
|||
|
|
# Model Scaling
|
|||
|
|
|
|||
|
|
</header>
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
<header>
|
|||
|
|
|
|||
|
|
# Dataset Scaling
|
|||
|
|
|
|||
|
|
</header>
|
|||
|
|
|
|||
|
|
| Dataset <br> size (h) | English <br> WER (↓) | Multilingual <br> WER (↓) | X→En <br> BLEU (↑) |
|
|||
|
|
| :-------------------: | :------------------: | :-----------------------: | :----------------: |
|
|||
|
|
| 3405 | 30.5 | 92.4 | 0.2 |
|
|||
|
|
| 6811 | 19.6 | 72.7 | 1.7 |
|
|||
|
|
| 13621 | 14.4 | 56.6 | 7.9 |
|
|||
|
|
| 27243 | 12.3 | 45.0 | 13.9 |
|
|||
|
|
| 54486 | 10.9 | 36.4 | 19.2 |
|
|||
|
|
| 681070 | **9.9** | **29.2** | **24.8** |
|
|||
|
|
|
|||
|
|
<!-- The general trend across tasks of diminishing returns when moving from 54,000 hours to our full dataset size of 680,000 hours could suggest that the current best Whisper models are under-trained relative to dataset size and performance could be further improved by a combination of longer training and larger models. It could also suggest that we are nearing the end of performance improvements from dataset size scaling for speech recognition. Further analysis is needed to characterize “scaling laws” for speech recognition in order to decided between these explanations. -->
|
|||
|
|
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
<header>
|
|||
|
|
|
|||
|
|
# Dataset scaling
|
|||
|
|
|
|||
|
|
</header>
|
|||
|
|
|
|||
|
|

|
|||
|
|

|