---
marp: true
paginate: true
author: Laurent Fainsin
math: katex
---
# Whisper
Robust Speech Recognition via Large-Scale Weak Supervision
---
- The trend is toward unsupervised learning (Wav2Vec 2.0, 1M hours of training data) $\rightarrow$ good audio encoders but fine-tuning required.
- Pre-training on multiple supervised datasets and domains improves speech recognition robustness and generalization.
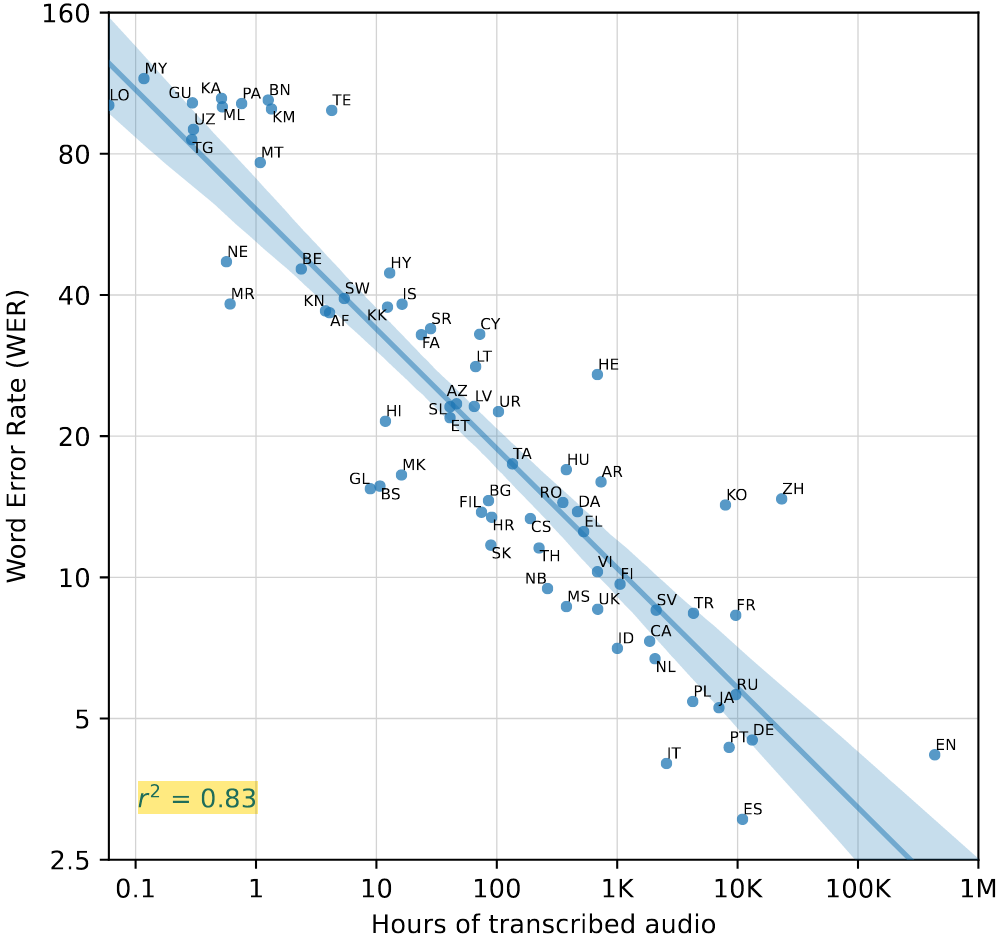
- Limited availability of labeled data in speech recognition, current datasets like [SpeechStew](https://arxiv.org/abs/2104.02133) only totals 5,140 hours of supervision.
- Recent efforts to create larger datasets for speech recognition by relaxing the requirement of gold-standard human-validated transcripts.
- Trade-off between quality and quantity, similar to computer vision where larger weakly supervised datasets significantly improve model robustness and generalization.
---
# Dataset & Data Processing
- Broad distribution of audio from many different environments, recording setups, speakers, and languages, salvaged from the internet.
- Audio language detector and heuristics to detect and filter bad/duplicate transcriptions.
- New dataset: 680,000 hours of weakly labeled audio data, including 117,000 hours of audio for 96 other languages and 125,000 hours of english translation data.
---

---
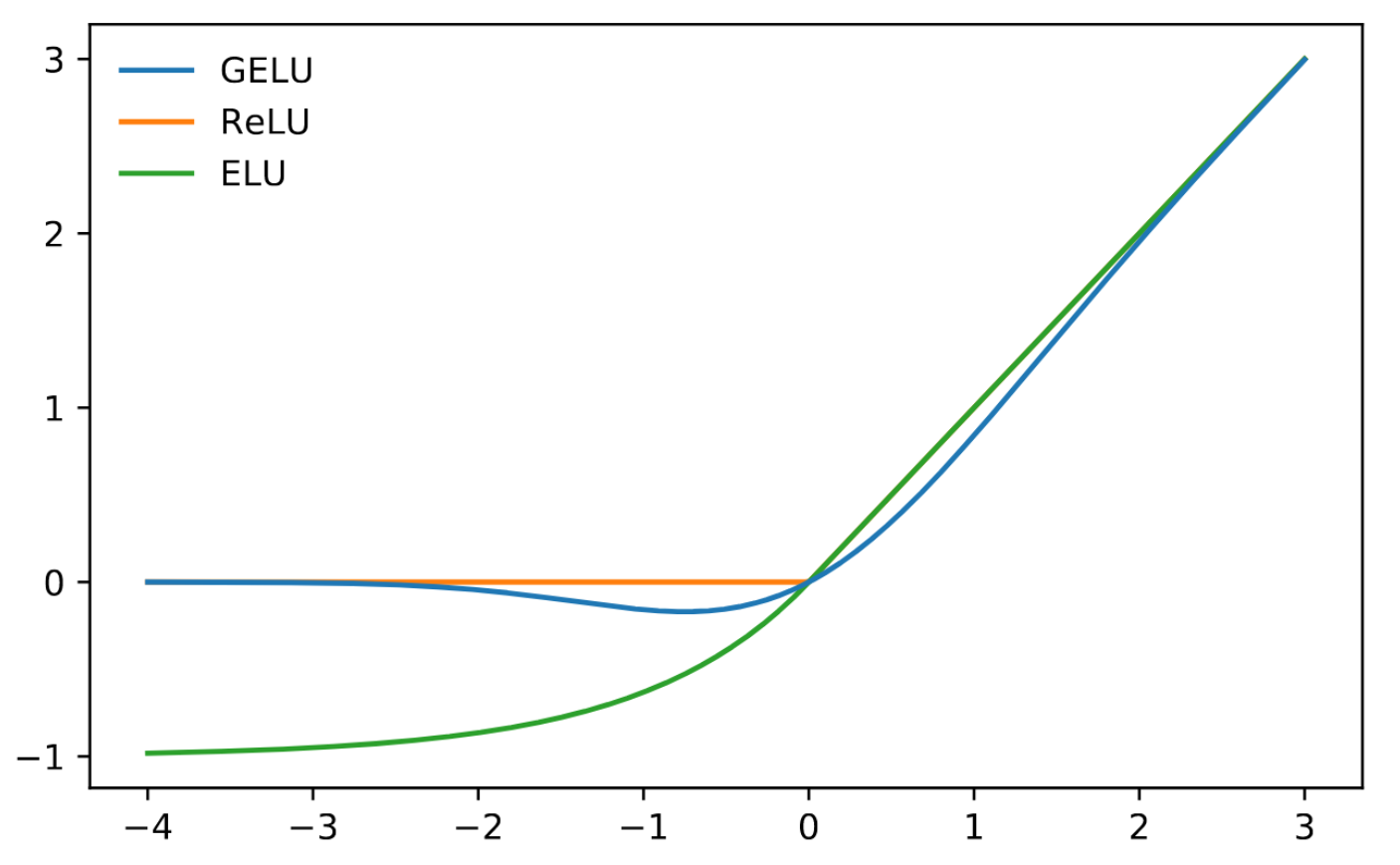
# [GELU](https://paperswithcode.com/method/gelu)
---
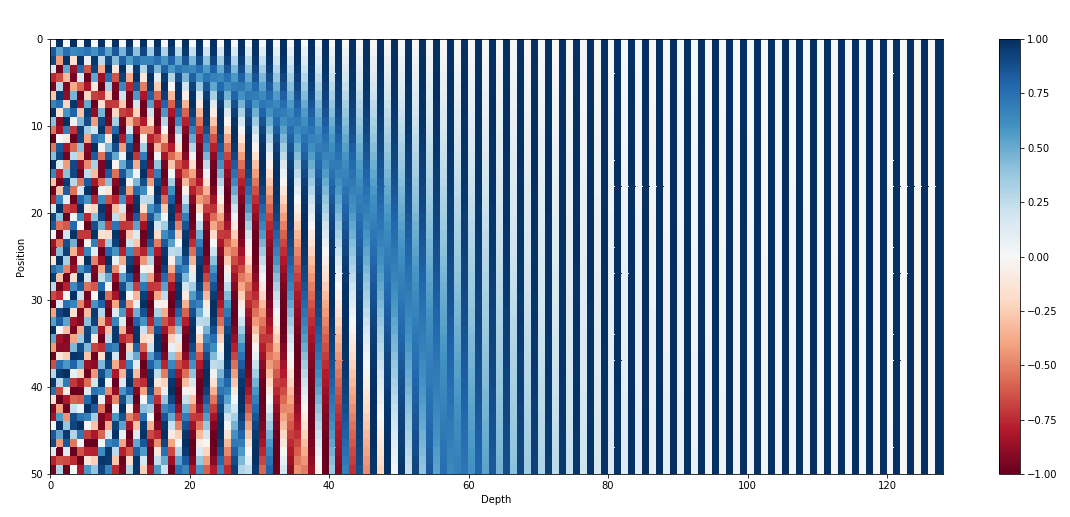
# Sinusoidal position embeddings
---
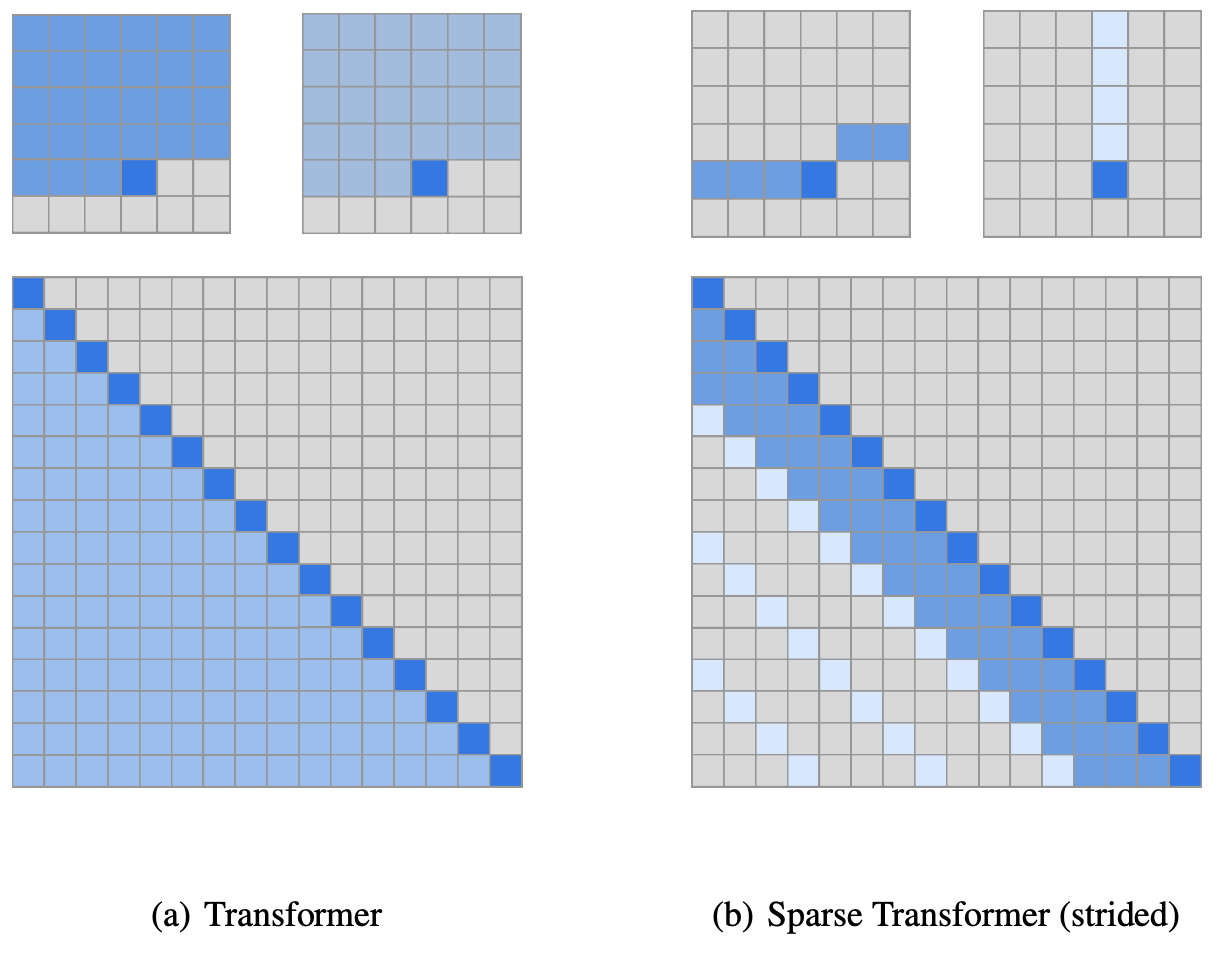
# [Sparse
Transformer](https://openai.com/blog/sparse-transformer/)
---

---
| Hyperparameter | Value |
| :-------------------------------- | :----------: |
| Updates | 1048576 |
| Batch Size | 256 |
| Warmup Updates | 2048 |
| Max grad norm | 1.0 |
| Optimizer | AdamW |
| β1 | 0.9 |
| β2 | 0.98 |
| ε | 10−6 |
| Weight Decay | 0.1 |
| Weight Init Gaussian | Fan-In |
| Learning Rate Schedule | Linear Decay |
| Speechless audio subsample factor | 10× |
| Condition on prior text rate | 50% |
---
$$\text{WER} = \frac{S + D + I}{N} = \frac{S + D + I}{S + D + C}$$
$S$ is the number of substitutions
$D$ is the number of deletions
$I$ is the number of insertions
$C$ is the number of correct words
$N$ is the number of words in the reference
$(N=S+D+C)$
---
| Dataset | wav2vec 2.0
Large (no LM) | Whisper
Large V2 | RER
(%) |
| :---------------- | :----------------------------: | :-------------------: | :-------------------------------------: |
| LibriSpeech Clean | **2.7** | **2.7** | 0.0 |
| Artie | 24.5 | **6.2** | 74.7 |
| Common Voice | 29.9 | **9.0** | 69.9 |
| Fleurs En | 14.6 | **4.4** | 69.9 |
| Tedlium | 10.5 | **4.0** | 61.9 |
| CHiME6 | 65.8 | **25.5** | 61.2 |
| VoxPopuli En | 17.9 | **7.3** | 59.2 |
| CORAAL | 35.6 | **16.2** | 54.5 |
| AMI IHM | 37.0 | **16.9** | 54.3 |
| Switchboard | 28.3 | **13.8** | 51.2 |
| CallHome | 34.8 | **17.6** | 49.4 |
| WSJ | 7.7 | **3.9** | 49.4 |
| AMI SDM1 | 67.6 | **36.4** | 46.2 |
| LibriSpeech Other | 6.2 | **5.2** | 16.1 |
| Average | 29.3 | **12.8** | 55.2 |

---
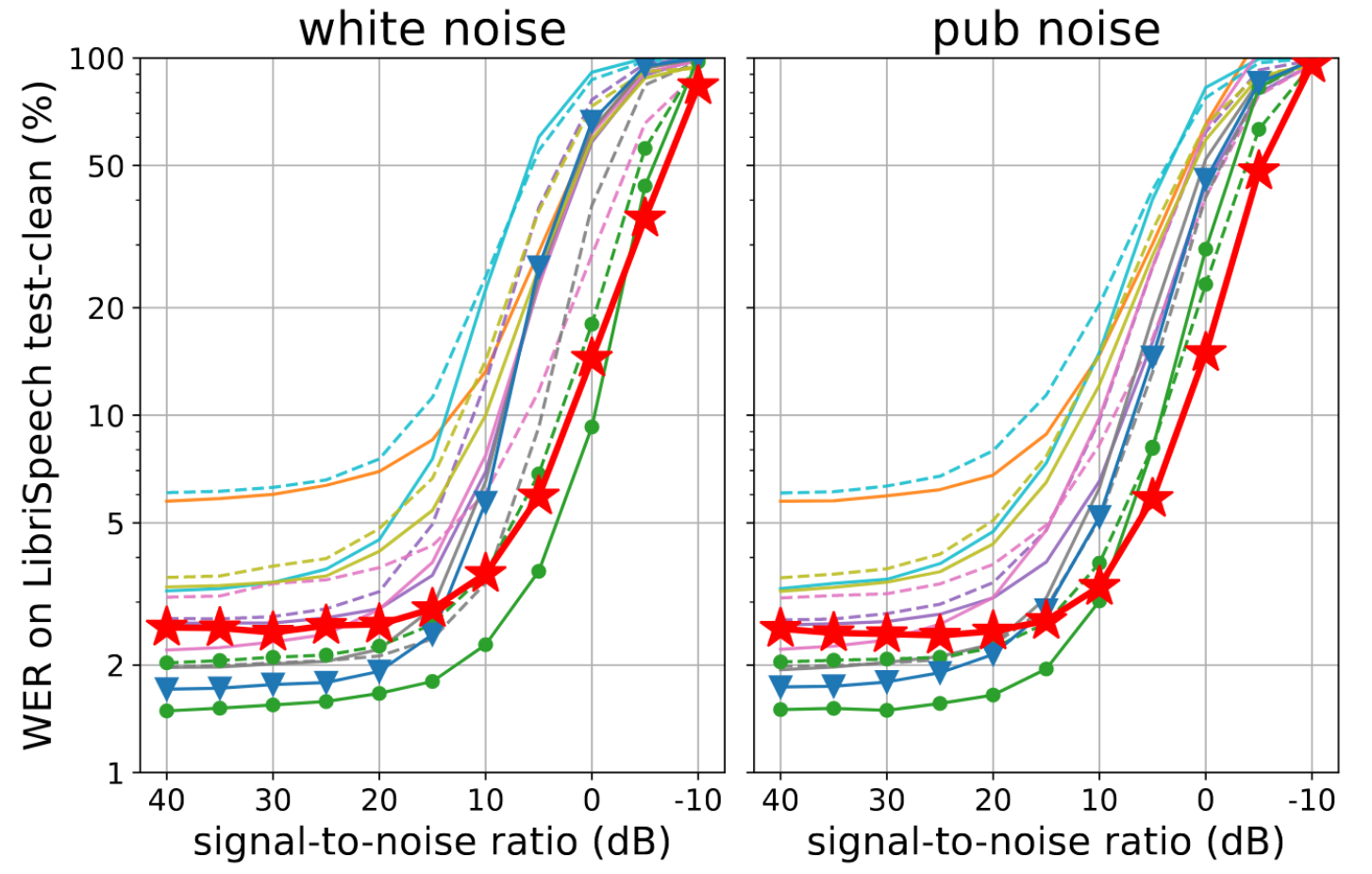

---
# Human comparison & improvements
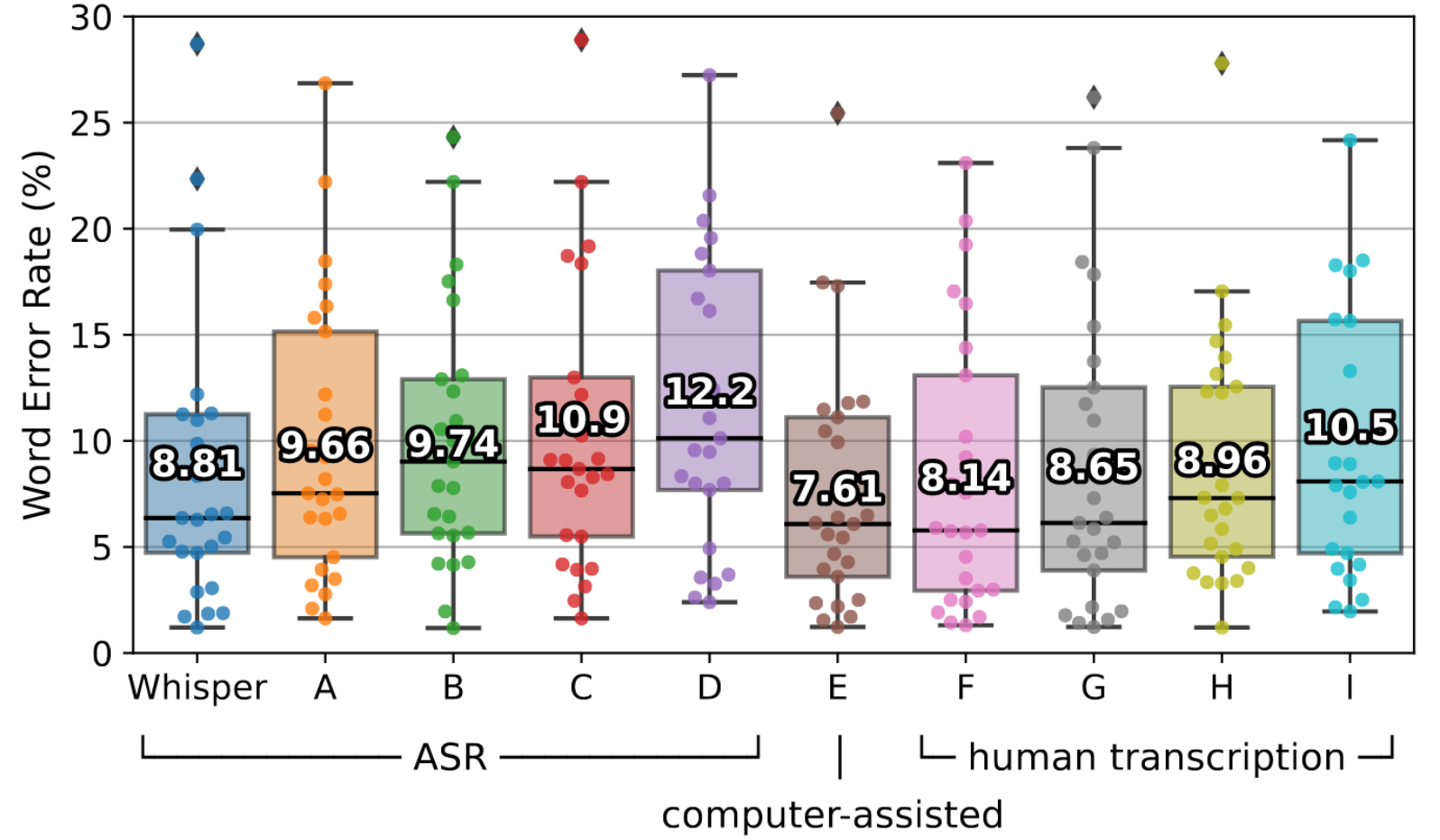

---
| Model | Layers | Width | Heads | Parameters | Required VRAM | Relative speed |
| :----- | :----: | :---: | :---: | :--------: | :-----------: | :------------: |
| Tiny | 4 | 384 | 6 | 39M | ~1 GB | ~32x |
| Base | 6 | 512 | 8 | 74M | ~1 GB | ~16x |
| Small | 12 | 768 | 12 | 244M | ~2 GB | ~6x |
| Medium | 24 | 1024 | 16 | 769M | ~5 GB | ~2x |
| Large | 32 | 1280 | 20 | 1550M | ~10 GB | 1x |
---

---
| Dataset
size (h) | English
WER (↓) | Multilingual
WER (↓) | X→En
BLEU (↑) |
| :-------------------: | :------------------: | :-----------------------: | :----------------: |
| 3405 | 30.5 | 92.4 | 0.2 |
| 6811 | 19.6 | 72.7 | 1.7 |
| 13621 | 14.4 | 56.6 | 7.9 |
| 27243 | 12.3 | 45.0 | 13.9 |
| 54486 | 10.9 | 36.4 | 19.2 |
| 681070 | **9.9** | **29.2** | **24.8** |
---