yay slides
This commit is contained in:
commit
0ceeaebfee
6
.vscode/extensions.json
vendored
Normal file
6
.vscode/extensions.json
vendored
Normal file
|
|
@ -0,0 +1,6 @@
|
|||
{
|
||||
"recommendations": [
|
||||
"marp-team.marp-vscode",
|
||||
"yzhang.markdown-all-in-one"
|
||||
]
|
||||
}
|
||||
4
.vscode/settings.json
vendored
Normal file
4
.vscode/settings.json
vendored
Normal file
|
|
@ -0,0 +1,4 @@
|
|||
{
|
||||
"markdown.marp.enableHtml":true,
|
||||
"editor.formatOnSave": true,
|
||||
}
|
||||
317
slides.md
Normal file
317
slides.md
Normal file
|
|
@ -0,0 +1,317 @@
|
|||
---
|
||||
marp: true
|
||||
paginate: true
|
||||
author: Clément Contet, Laurent Fainsin
|
||||
---
|
||||
|
||||
<style>
|
||||
section::after {
|
||||
/*custom pagination*/
|
||||
content: attr(data-marpit-pagination) ' / ' attr(data-marpit-pagination-total);
|
||||
}
|
||||
</style>
|
||||
|
||||
# The Raft Consensus Algorithm
|
||||
|
||||
<!-- https://github.com/raft/raft.github.io -->
|
||||
<!-- https://ongardie.net/static/coreosfest/slides -->
|
||||
|
||||

|
||||
|
||||
<footer>
|
||||
Diego Ongaro,
|
||||
John Ousterhout,
|
||||
Stanford University
|
||||
</footer>
|
||||
|
||||
---
|
||||
|
||||
<!-- Qu'est ce que le "consensus" dans un premier temps ? -->
|
||||
|
||||
<header>
|
||||
|
||||
# Consensus ?
|
||||
|
||||
</header>
|
||||
|
||||
> Consensus algorithms allow a collection of machines to work as a coherent group that can survive the failures of some of its members. – RAFT authors
|
||||
|
||||
<br>
|
||||
|
||||
- Accord sur l'état partagé (image système unique)
|
||||
- Réparation autonome en cas de défaillance d'un serveur
|
||||
- Une minorité de serveurs HS: pas de problème
|
||||
- La majorité des serveurs HS: perte de disponibilité, maintien de la cohérence
|
||||
- La clé pour construire des systèmes de stockage cohérents
|
||||
|
||||
<!-- Le consensus permet à plusieurs machines de se mettre d'accord, de former un groupe cohérent, capable de prendre des decisions, même si certains membres sont défaillants. -->
|
||||
|
||||
---
|
||||
|
||||
<header>
|
||||
|
||||
# Architecture typique des systèmes de consensus
|
||||
|
||||

|
||||
|
||||
<!--
|
||||
|
||||
- Replicated log -> replicated state machine
|
||||
- All servers execute same commands in same order
|
||||
- Consensus module ensures proper log replication
|
||||
- System makes progress as long as any majority of servers up
|
||||
- Failure model: fail-stop (not Byzantine), delayed/lost msgs
|
||||
|
||||
-->
|
||||
|
||||
</header>
|
||||
|
||||
---
|
||||
|
||||
<header>
|
||||
|
||||
# Motivation ?
|
||||
|
||||
</header>
|
||||
|
||||
<!-- Avant RAFT il existait déjà un algorithme bien connu du nom de Paxos qui dominait sur le reste des algos de consensus. -->
|
||||
|
||||
<!-- Alors pourquoi faire un nouvel algo ? quels sont les motivations des auteurs ? -->
|
||||
|
||||
Paxos domine le marché depuis ~25 ans (Leslie Lamport, 1989)
|
||||
- Difficile à comprendre
|
||||
- Difficile à implémenter
|
||||
|
||||
> The dirty little secret of the NSDI community is that at most five people really, truly understand every part of Paxos ;-). – [NSDI](https://www.usenix.org/conference/nsdi23) reviewer
|
||||
|
||||
> There are significant gaps between the description of the Paxos algorithm and the needs of a real-world system…the final system will be based on an unproven protocol. – [Chubby](https://research.google/pubs/pub27897/) authors
|
||||
|
||||
---
|
||||
|
||||
<header>
|
||||
|
||||
# Pourquoi RAFT ?
|
||||
|
||||
</header>
|
||||
|
||||
<!-- Les auteurs de RAFT en avait donc ras le bol de voir cette situation, ils ont donc décidés de créer un nouvel algorithme, en se fondant sur la compréhensibilité -->
|
||||
|
||||
## Prendre des décisions de conception fondées sur la compréhensibilité
|
||||
|
||||
<!-- Pour se faire ils ont choisis de décomposer le consensus le plus possible en des petits problèmes trivials à résoudre. -->
|
||||
|
||||
- Décomposition du problème
|
||||
|
||||
<!-- Il ont aussi essayé de diminuer l'espace des états possibles lors du fonctionnement de l'algorithme pour le rendre le plus simple possible. -->
|
||||
|
||||
- Minimiser l'espace des états
|
||||
- Traiter plusieurs problèmes avec un seul mécanisme
|
||||
- Éliminer les cas particuliers
|
||||
- Minimiser le non-déterminisme
|
||||
- Maximiser la cohérence
|
||||
|
||||
---
|
||||
|
||||
<header>
|
||||
|
||||
# Décomposition du problème
|
||||
|
||||
</header>
|
||||
|
||||
1. Élection d'un leader (mandat)
|
||||
- Sélectionner un serveur qui sera le leader
|
||||
- Détecter les pannes, choisir un nouveau leader
|
||||
2. Réplication des logs (fonctionnement normal)
|
||||
- Le leader accepte les commandes des clients et les ajoute à son journal.
|
||||
- Le leader réplique son journal aux autres serveurs (écrase les incohérences).
|
||||
3. Sécurité
|
||||
- Maintenir la cohérence des journaux
|
||||
- Seuls les serveurs dont les journaux sont à jour peuvent devenir des leaders.
|
||||
|
||||
---
|
||||
|
||||
<header>
|
||||
|
||||
# Minimiser l'espace des états
|
||||
|
||||
</header>
|
||||
|
||||
<!-- Il n'y a que 3 états possibles pour les serveurs ! -->
|
||||
|
||||
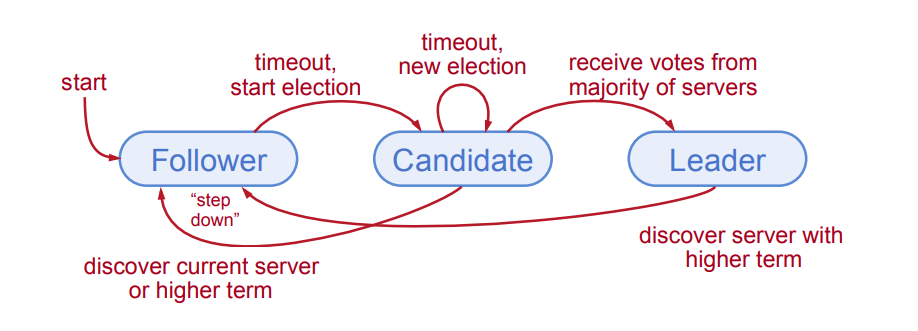
|
||||
|
||||
<!--
|
||||
|
||||
Follower: Passive (but expects regular heartbeats)
|
||||
|
||||
Candidate: Issues RequestVote RPCs to get elected as leader
|
||||
|
||||
Leader: Issues AppendEntries RPCs:
|
||||
- Replicate its log
|
||||
- Heartbeats to maintain leadership
|
||||
|
||||
-->
|
||||
|
||||
---
|
||||
|
||||
<header>
|
||||
|
||||
# Mandats
|
||||
|
||||
</header>
|
||||
|
||||
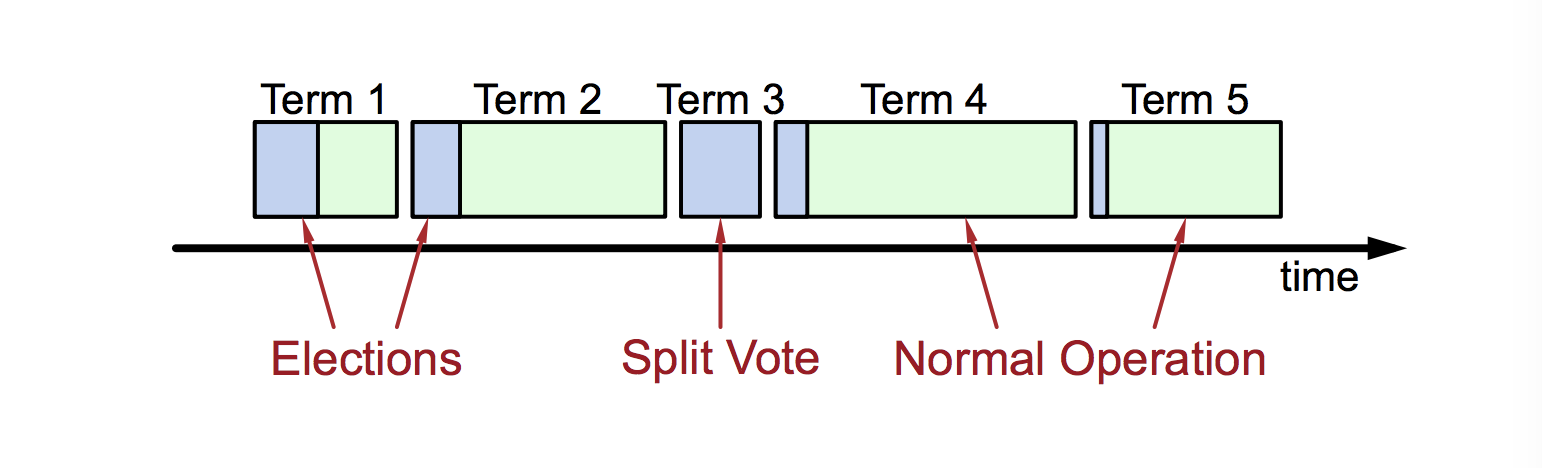
|
||||
|
||||
<!--
|
||||
|
||||
- At most 1 leader per term
|
||||
- Some terms have no leader (failed election)
|
||||
- Each server maintains current term value (no global view)
|
||||
- Exchanged in every RPC
|
||||
- Peer has later term? Update term, revert to follower
|
||||
- Incoming RPC has obsolete term? Reply with error
|
||||
|
||||
Terms identify obsolete information
|
||||
|
||||
-->
|
||||
|
||||
---
|
||||
|
||||
<header>
|
||||
|
||||
# Leader Election
|
||||
|
||||
</header>
|
||||
|
||||
TODO
|
||||
|
||||
---
|
||||
|
||||
<header>
|
||||
|
||||
# Election Correctness
|
||||
|
||||
</header>
|
||||
|
||||
TODO
|
||||
|
||||
---
|
||||
|
||||
<header>
|
||||
|
||||
# Démo interactive
|
||||
|
||||
</header>
|
||||
|
||||
<iframe
|
||||
src="https://raft.github.io/raftscope/index.html"
|
||||
frameborder="0"
|
||||
scrolling="no"
|
||||
height=100%
|
||||
width=100%
|
||||
></iframe>
|
||||
|
||||
<!--
|
||||
|
||||
Normal Operation:
|
||||
|
||||
- Client sends command to leader
|
||||
- Leader appends command to its log
|
||||
- Leader sends AppendEntries RPCs to all followers
|
||||
- Once new entry committed:
|
||||
- Leader executes command in its state machine, returns result to client
|
||||
- Leader notifies followers of committed entries in subsequent AppendEntries RPCs
|
||||
- Followers execute committed commands in their state machines
|
||||
- Crashed/slow followers?
|
||||
-Leader retries AppendEntries RPCs until they succeed
|
||||
- Optimal performance in common case:
|
||||
- One successful RPC to any majority of servers
|
||||
|
||||
-->
|
||||
|
||||
---
|
||||
|
||||
<header>
|
||||
|
||||
# Log Structure
|
||||
|
||||
</header>
|
||||
|
||||
TODO
|
||||
|
||||
---
|
||||
|
||||
<header>
|
||||
|
||||
# Log Inconsistencies
|
||||
|
||||
</header>
|
||||
|
||||
TODO
|
||||
|
||||
---
|
||||
|
||||
<header>
|
||||
|
||||
# Log Matching Property
|
||||
|
||||
</header>
|
||||
|
||||
TODO
|
||||
|
||||
---
|
||||
|
||||
<header>
|
||||
|
||||
# De nombreuses implémentations
|
||||
|
||||
</header>
|
||||
|
||||
| Name | Primary Authors | Language | License |
|
||||
| :------------- | :------------------------------------------------ | :--------- | :--------- |
|
||||
| etcd/raft | Blake Mizerany, Xiang Li and Yicheng Qin (CoreOS) | Go | Apache 2.0 |
|
||||
| go-raft | Ben Johnson (Sky) and Xiang Li (CMU, CoreOS) | Go | MIT |
|
||||
| hashicorp/raft | Armon Dadgar (hashicorp) | Go | MPL-2.0 |
|
||||
| copycat | Jordan Halterman | Java | Apache2 |
|
||||
| LogCabin | Diego Ongaro (Stanford, Scale Computing) | C++ | ISC |
|
||||
| akka-raft | Konrad Malawski | Scala | Apache2 |
|
||||
| kanaka/raft.js | Joel Martin | Javascript | MPL-2.0 |
|
||||
|
||||
---
|
||||
|
||||
<header>
|
||||
|
||||
# How much randomization is needed to avoid split votes?
|
||||
|
||||
</header>
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
<header>
|
||||
|
||||
# User Study: Is Raft Simpler than Paxos?
|
||||
|
||||
</header>
|
||||
|
||||
<!--
|
||||
|
||||
- 43 students in 2 graduate OS classes (Berkeley and Stanford)
|
||||
- Group 1: Raft video, Raft quiz, then Paxos video, Paxos quiz
|
||||
- Group 2: Paxos video, Paxos quiz, then Raft video, Raft quiz
|
||||
- Instructional videos:
|
||||
- Same instructor (Ousterhout)
|
||||
- Covered same functionality: consensus, replicated log, cluster reconfiguration
|
||||
- Fleshed out missing pieces for Paxos
|
||||
- Videos available on YouTube
|
||||
- Quizzes:
|
||||
- Questions in 3 general categories
|
||||
- Same weightings for both tests
|
||||
- Experiment favored Paxos slightly:
|
||||
- 15 students had prior experience with Paxos
|
||||
|
||||
-->
|
||||
|
||||

|
||||

|
||||
Loading…
Reference in a new issue