mirror of
https://github.com/finegrain-ai/refiners.git
synced 2024-11-21 13:48:46 +00:00
(doc/fluxion/attention) add/convert docstrings to mkdocstrings format
This commit is contained in:
parent
e3238a6af5
commit
0fc3264fae
|
|
@ -3,7 +3,7 @@ import math
|
|||
import torch
|
||||
from jaxtyping import Float
|
||||
from torch import Tensor, device as Device, dtype as DType
|
||||
from torch.nn.functional import scaled_dot_product_attention as _scaled_dot_product_attention # type: ignore
|
||||
from torch.nn.functional import scaled_dot_product_attention as _scaled_dot_product_attention
|
||||
|
||||
from refiners.fluxion.context import Contexts
|
||||
from refiners.fluxion.layers.basics import Identity
|
||||
|
|
@ -18,19 +18,37 @@ def scaled_dot_product_attention(
|
|||
value: Float[Tensor, "batch target_sequence_length dim"],
|
||||
is_causal: bool = False,
|
||||
) -> Float[Tensor, "batch source_sequence_length dim"]:
|
||||
return _scaled_dot_product_attention(query, key, value, is_causal=is_causal) # type: ignore
|
||||
"""Scaled Dot Product Attention.
|
||||
|
||||
Optimization depends on which pytorch backend is used.
|
||||
See [[arXiv:1706.03762] Attention Is All You Need (Equation 1)](https://arxiv.org/abs/1706.03762) for more details.
|
||||
See also [torch.nn.functional.scaled_dot_product_attention](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html).
|
||||
"""
|
||||
return _scaled_dot_product_attention(
|
||||
query=query,
|
||||
key=key,
|
||||
value=value,
|
||||
is_causal=is_causal,
|
||||
)
|
||||
|
||||
|
||||
def sparse_dot_product_attention_non_optimized(
|
||||
def scaled_dot_product_attention_non_optimized(
|
||||
query: Float[Tensor, "batch source_sequence_length dim"],
|
||||
key: Float[Tensor, "batch target_sequence_length dim"],
|
||||
value: Float[Tensor, "batch target_sequence_length dim"],
|
||||
is_causal: bool = False,
|
||||
) -> Float[Tensor, "batch source_sequence_length dim"]:
|
||||
"""Non-optimized Scaled Dot Product Attention.
|
||||
|
||||
See [[arXiv:1706.03762] Attention Is All You Need (Equation 1)](https://arxiv.org/abs/1706.03762) for more details.
|
||||
"""
|
||||
if is_causal:
|
||||
# TODO: implement causal attention
|
||||
raise NotImplementedError("Causal attention for non_optimized attention is not yet implemented")
|
||||
_, _, _, dim = query.shape
|
||||
raise NotImplementedError(
|
||||
"Causal attention for `scaled_dot_product_attention_non_optimized` is not yet implemented"
|
||||
)
|
||||
|
||||
dim = query.shape[-1]
|
||||
attention = query @ key.permute(0, 1, 3, 2)
|
||||
attention = attention / math.sqrt(dim)
|
||||
attention = torch.softmax(input=attention, dim=-1)
|
||||
|
|
@ -38,20 +56,58 @@ def sparse_dot_product_attention_non_optimized(
|
|||
|
||||
|
||||
class ScaledDotProductAttention(Module):
|
||||
"""Scaled Dot Product Attention.
|
||||
|
||||
??? note "See [[arXiv:1706.03762] Attention Is All You Need (Figure 2)](https://arxiv.org/abs/1706.03762) for more details"
|
||||
|
||||
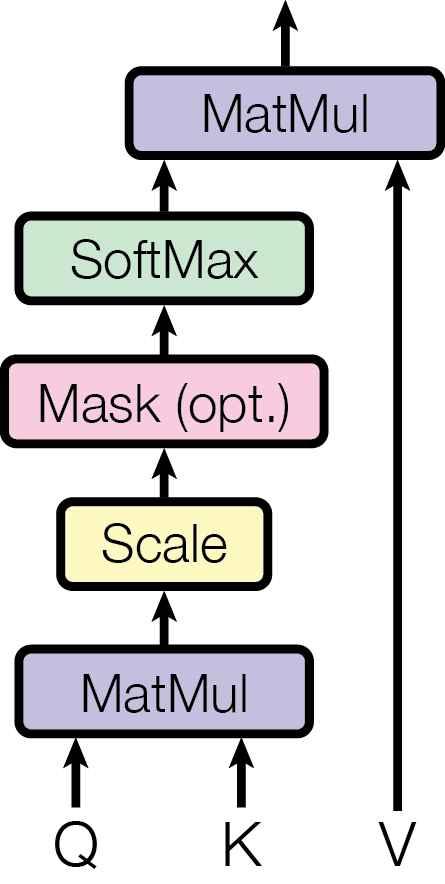
|
||||
|
||||
Note:
|
||||
This layer simply wraps `scaled_dot_product_attention` inside an `fl.Module`.
|
||||
|
||||
Receives:
|
||||
Query (Float[Tensor, "batch num_queries embedding_dim"]):
|
||||
Key (Float[Tensor, "batch num_keys embedding_dim"]):
|
||||
Value (Float[Tensor, "batch num_values embedding_dim"]):
|
||||
|
||||
Returns:
|
||||
(Float[Tensor, "batch num_queries embedding_dim"]):
|
||||
|
||||
Example:
|
||||
```py
|
||||
attention = fl.ScaledDotProductAttention(num_heads=8)
|
||||
|
||||
query = torch.randn(2, 10, 128)
|
||||
key = torch.randn(2, 10, 128)
|
||||
value = torch.randn(2, 10, 128)
|
||||
output = attention(query, key, value)
|
||||
|
||||
assert output.shape == (2, 10, 128)
|
||||
```
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
num_heads: int = 1,
|
||||
is_causal: bool | None = None,
|
||||
is_causal: bool = False,
|
||||
is_optimized: bool = True,
|
||||
slice_size: int | None = None,
|
||||
) -> None:
|
||||
"""Initialize the Scaled Dot Product Attention layer.
|
||||
|
||||
Args:
|
||||
num_heads: The number of heads to use.
|
||||
is_causal: Whether to use causal attention.
|
||||
is_optimized: Whether to use optimized attention.
|
||||
slice_size: The slice size to use for the optimized attention.
|
||||
"""
|
||||
super().__init__()
|
||||
self.num_heads = num_heads
|
||||
self.is_causal = is_causal
|
||||
self.is_optimized = is_optimized
|
||||
self.slice_size = slice_size
|
||||
self.dot_product = (
|
||||
scaled_dot_product_attention if self.is_optimized else sparse_dot_product_attention_non_optimized
|
||||
scaled_dot_product_attention if self.is_optimized else scaled_dot_product_attention_non_optimized
|
||||
)
|
||||
|
||||
def forward(
|
||||
|
|
@ -59,12 +115,20 @@ class ScaledDotProductAttention(Module):
|
|||
query: Float[Tensor, "batch num_queries embedding_dim"],
|
||||
key: Float[Tensor, "batch num_keys embedding_dim"],
|
||||
value: Float[Tensor, "batch num_values embedding_dim"],
|
||||
is_causal: bool | None = None,
|
||||
) -> Float[Tensor, "batch num_queries dim"]:
|
||||
if self.slice_size is None:
|
||||
return self._process_attention(query, key, value, is_causal)
|
||||
|
||||
return self._sliced_attention(query, key, value, is_causal=is_causal, slice_size=self.slice_size)
|
||||
) -> Float[Tensor, "batch num_queries embedding_dim"]:
|
||||
if self.slice_size:
|
||||
return self._sliced_attention(
|
||||
query=query,
|
||||
key=key,
|
||||
value=value,
|
||||
slice_size=self.slice_size,
|
||||
)
|
||||
else:
|
||||
return self._process_attention(
|
||||
query=query,
|
||||
key=key,
|
||||
value=value,
|
||||
)
|
||||
|
||||
def _sliced_attention(
|
||||
self,
|
||||
|
|
@ -72,14 +136,19 @@ class ScaledDotProductAttention(Module):
|
|||
key: Float[Tensor, "batch num_keys embedding_dim"],
|
||||
value: Float[Tensor, "batch num_values embedding_dim"],
|
||||
slice_size: int,
|
||||
is_causal: bool | None = None,
|
||||
) -> Float[Tensor, "batch num_queries dim"]:
|
||||
) -> Float[Tensor, "batch num_queries embedding_dim"]:
|
||||
"""Compute the scaled dot product attention in slices.
|
||||
|
||||
This is useful when the input tensors are too large to be processed in one go.
|
||||
"""
|
||||
_, num_queries, _ = query.shape
|
||||
output = torch.zeros_like(query)
|
||||
for start_idx in range(0, num_queries, slice_size):
|
||||
end_idx = min(start_idx + slice_size, num_queries)
|
||||
output[:, start_idx:end_idx, :] = self._process_attention(
|
||||
query[:, start_idx:end_idx, :], key, value, is_causal
|
||||
query=query[:, start_idx:end_idx, :],
|
||||
key=key,
|
||||
value=value,
|
||||
)
|
||||
return output
|
||||
|
||||
|
|
@ -88,37 +157,84 @@ class ScaledDotProductAttention(Module):
|
|||
query: Float[Tensor, "batch num_queries embedding_dim"],
|
||||
key: Float[Tensor, "batch num_keys embedding_dim"],
|
||||
value: Float[Tensor, "batch num_values embedding_dim"],
|
||||
is_causal: bool | None = None,
|
||||
) -> Float[Tensor, "batch num_queries dim"]:
|
||||
return self.merge_multi_head(
|
||||
) -> Float[Tensor, "batch num_queries embedding_dim"]:
|
||||
"""Compute the scaled dot product attention.
|
||||
|
||||
Split the input tensors (query, key, value) into multiple heads along the embedding dimension,
|
||||
then compute the scaled dot product attention for each head, and finally merge the heads back.
|
||||
"""
|
||||
return self._merge_multi_head(
|
||||
x=self.dot_product(
|
||||
query=self.split_to_multi_head(query),
|
||||
key=self.split_to_multi_head(key),
|
||||
value=self.split_to_multi_head(value),
|
||||
is_causal=(
|
||||
is_causal if is_causal is not None else (self.is_causal if self.is_causal is not None else False)
|
||||
),
|
||||
query=self._split_to_multi_head(query),
|
||||
key=self._split_to_multi_head(key),
|
||||
value=self._split_to_multi_head(value),
|
||||
is_causal=self.is_causal,
|
||||
)
|
||||
)
|
||||
|
||||
def split_to_multi_head(
|
||||
self, x: Float[Tensor, "batch_size sequence_length embedding_dim"]
|
||||
def _split_to_multi_head(
|
||||
self,
|
||||
x: Float[Tensor, "batch_size sequence_length embedding_dim"],
|
||||
) -> Float[Tensor, "batch_size num_heads sequence_length (embedding_dim//num_heads)"]:
|
||||
"""Split the input tensor into multiple heads along the embedding dimension.
|
||||
|
||||
See also `merge_multi_head`, which is the inverse operation.
|
||||
"""
|
||||
assert (
|
||||
len(x.shape) == 3
|
||||
), f"Expected tensor with shape (batch_size sequence_length embedding_dim), got {x.shape}"
|
||||
x.ndim == 3
|
||||
), f"Expected input tensor with shape (batch_size sequence_length embedding_dim), got {x.shape}"
|
||||
assert (
|
||||
x.shape[-1] % self.num_heads == 0
|
||||
), f"Embedding dim (x.shape[-1]={x.shape[-1]}) must be divisible by num heads"
|
||||
), f"Expected embedding_dim (x.shape[-1]={x.shape[-1]}) to be divisible by num_heads ({self.num_heads})"
|
||||
|
||||
return x.reshape(x.shape[0], x.shape[1], self.num_heads, x.shape[-1] // self.num_heads).transpose(1, 2)
|
||||
|
||||
def merge_multi_head(
|
||||
self, x: Float[Tensor, "batch_size num_heads sequence_length heads_dim"]
|
||||
def _merge_multi_head(
|
||||
self,
|
||||
x: Float[Tensor, "batch_size num_heads sequence_length heads_dim"],
|
||||
) -> Float[Tensor, "batch_size sequence_length heads_dim * num_heads"]:
|
||||
"""Merge the input tensor from multiple heads along the embedding dimension.
|
||||
|
||||
See also `split_to_multi_head`, which is the inverse operation.
|
||||
"""
|
||||
return x.transpose(1, 2).reshape(x.shape[0], x.shape[2], self.num_heads * x.shape[-1])
|
||||
|
||||
|
||||
class Attention(Chain):
|
||||
"""Multi-Head Attention layer.
|
||||
|
||||
??? note "See [[arXiv:1706.03762] Attention Is All You Need (Figure 2)](https://arxiv.org/abs/1706.03762) for more details"
|
||||
|
||||
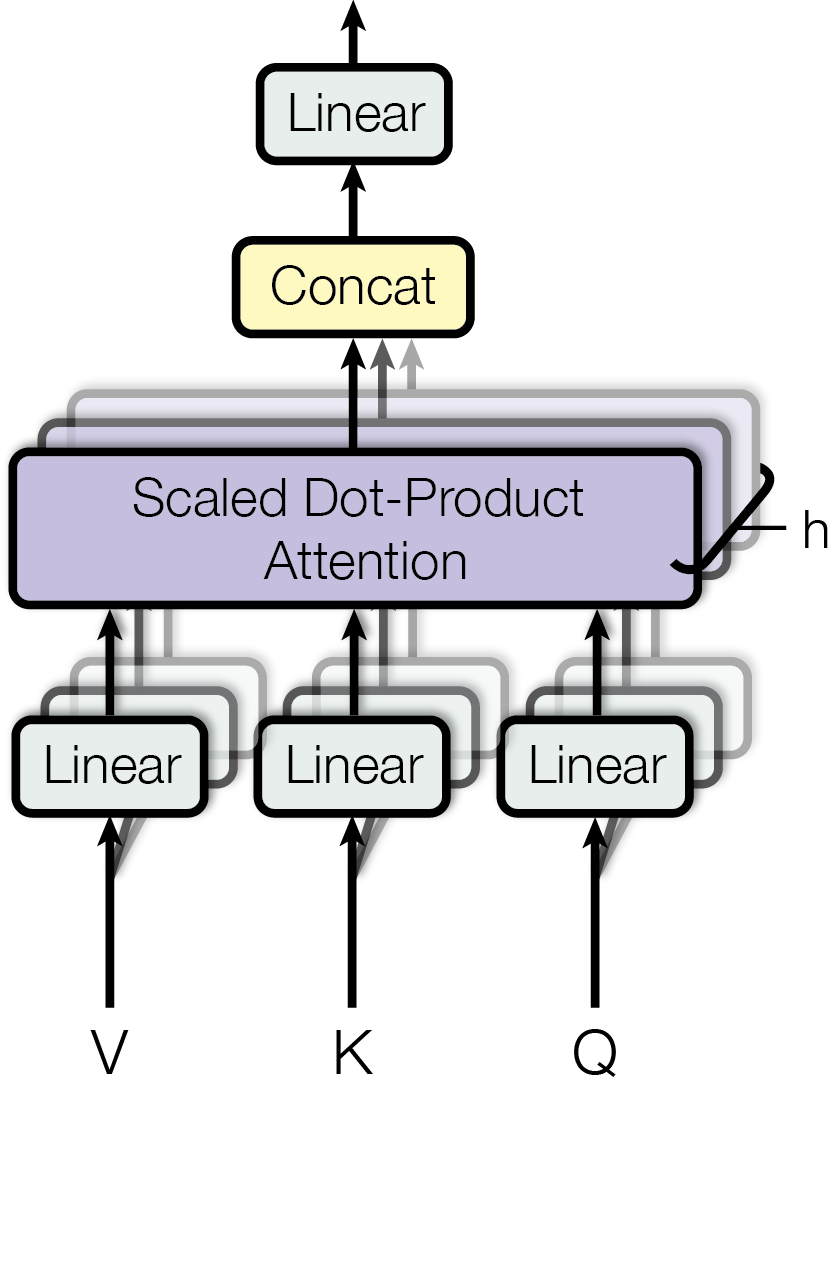
|
||||
|
||||
Note: This layer simply chains
|
||||
- a [`Distribute`][refiners.fluxion.layers.chain.Distribute] layer,
|
||||
containing 3 [`Linear`][refiners.fluxion.layers.linear.Linear] layers,
|
||||
which transforms the 3 inputs into Query, Key and Value
|
||||
- a [`ScaledDotProductAttention`][refiners.fluxion.layers.attentions.ScaledDotProductAttention] layer
|
||||
- a [`Linear`][refiners.fluxion.layers.linear.Linear] layer,
|
||||
which further transforms the output of the
|
||||
[`ScaledDotProductAttention`][refiners.fluxion.layers.attentions.ScaledDotProductAttention] layer
|
||||
|
||||
Receives:
|
||||
Query (Float[Tensor, "batch sequence_length embedding_dim"]):
|
||||
Key (Float[Tensor, "batch sequence_length embedding_dim"]):
|
||||
Value (Float[Tensor, "batch sequence_length embedding_dim"]):
|
||||
|
||||
Returns:
|
||||
(Float[Tensor, "batch sequence_length embedding_dim"]):
|
||||
|
||||
Example:
|
||||
```py
|
||||
attention = fl.Attention(num_heads=8, embedding_dim=128)
|
||||
|
||||
tensor = torch.randn(2, 10, 128)
|
||||
output = attention(tensor, tensor, tensor)
|
||||
|
||||
assert output.shape == (2, 10, 128)
|
||||
```
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
embedding_dim: int,
|
||||
|
|
@ -127,11 +243,25 @@ class Attention(Chain):
|
|||
value_embedding_dim: int | None = None,
|
||||
inner_dim: int | None = None,
|
||||
use_bias: bool = True,
|
||||
is_causal: bool | None = None,
|
||||
is_causal: bool = False,
|
||||
is_optimized: bool = True,
|
||||
device: Device | str | None = None,
|
||||
dtype: DType | None = None,
|
||||
) -> None:
|
||||
"""Initialize the Attention layer.
|
||||
|
||||
Args:
|
||||
embedding_dim: The embedding dimension of the input and output tensors.
|
||||
num_heads: The number of heads to use.
|
||||
key_embedding_dim: The embedding dimension of the key tensor.
|
||||
value_embedding_dim: The embedding dimension of the value tensor.
|
||||
inner_dim: The inner dimension of the linear layers.
|
||||
use_bias: Whether to use bias in the linear layers.
|
||||
is_causal: Whether to use causal attention.
|
||||
is_optimized: Whether to use optimized attention.
|
||||
device: The device to use.
|
||||
dtype: The dtype to use.
|
||||
"""
|
||||
assert (
|
||||
embedding_dim % num_heads == 0
|
||||
), f"embedding_dim {embedding_dim} must be divisible by num_heads {num_heads}"
|
||||
|
|
@ -144,23 +274,24 @@ class Attention(Chain):
|
|||
self.use_bias = use_bias
|
||||
self.is_causal = is_causal
|
||||
self.is_optimized = is_optimized
|
||||
|
||||
super().__init__(
|
||||
Distribute(
|
||||
Linear(
|
||||
Linear( # Query projection
|
||||
in_features=self.embedding_dim,
|
||||
out_features=self.inner_dim,
|
||||
bias=self.use_bias,
|
||||
device=device,
|
||||
dtype=dtype,
|
||||
),
|
||||
Linear(
|
||||
Linear( # Key projection
|
||||
in_features=self.key_embedding_dim,
|
||||
out_features=self.inner_dim,
|
||||
bias=self.use_bias,
|
||||
device=device,
|
||||
dtype=dtype,
|
||||
),
|
||||
Linear(
|
||||
Linear( # Value projection
|
||||
in_features=self.value_embedding_dim,
|
||||
out_features=self.inner_dim,
|
||||
bias=self.use_bias,
|
||||
|
|
@ -168,8 +299,12 @@ class Attention(Chain):
|
|||
dtype=dtype,
|
||||
),
|
||||
),
|
||||
ScaledDotProductAttention(num_heads=num_heads, is_causal=is_causal, is_optimized=is_optimized),
|
||||
Linear(
|
||||
ScaledDotProductAttention(
|
||||
num_heads=num_heads,
|
||||
is_causal=is_causal,
|
||||
is_optimized=is_optimized,
|
||||
),
|
||||
Linear( # Output projection
|
||||
in_features=self.inner_dim,
|
||||
out_features=self.embedding_dim,
|
||||
bias=True,
|
||||
|
|
@ -180,17 +315,54 @@ class Attention(Chain):
|
|||
|
||||
|
||||
class SelfAttention(Attention):
|
||||
"""Multi-Head Self-Attention layer.
|
||||
|
||||
Note: This layer simply chains
|
||||
- a [`Parallel`][refiners.fluxion.layers.chain.Parallel] layer,
|
||||
which duplicates the input Tensor
|
||||
(for each Linear layer in the `Attention` layer)
|
||||
- an [`Attention`][refiners.fluxion.layers.attentions.Attention] layer
|
||||
|
||||
Receives:
|
||||
(Float[Tensor, "batch sequence_length embedding_dim"]):
|
||||
|
||||
Returns:
|
||||
(Float[Tensor, "batch sequence_length embedding_dim"]):
|
||||
|
||||
Example:
|
||||
```py
|
||||
self_attention = fl.SelfAttention(num_heads=8, embedding_dim=128)
|
||||
|
||||
tensor = torch.randn(2, 10, 128)
|
||||
output = self_attention(tensor)
|
||||
|
||||
assert output.shape == (2, 10, 128)
|
||||
```
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
embedding_dim: int,
|
||||
inner_dim: int | None = None,
|
||||
num_heads: int = 1,
|
||||
use_bias: bool = True,
|
||||
is_causal: bool | None = None,
|
||||
is_causal: bool = False,
|
||||
is_optimized: bool = True,
|
||||
device: Device | str | None = None,
|
||||
dtype: DType | None = None,
|
||||
) -> None:
|
||||
"""Initialize the Self-Attention layer.
|
||||
|
||||
Args:
|
||||
embedding_dim: The embedding dimension of the input and output tensors.
|
||||
inner_dim: The inner dimension of the linear layers.
|
||||
num_heads: The number of heads to use.
|
||||
use_bias: Whether to use bias in the linear layers.
|
||||
is_causal: Whether to use causal attention.
|
||||
is_optimized: Whether to use optimized attention.
|
||||
device: The device to use.
|
||||
dtype: The dtype to use.
|
||||
"""
|
||||
super().__init__(
|
||||
embedding_dim=embedding_dim,
|
||||
inner_dim=inner_dim,
|
||||
|
|
@ -201,22 +373,67 @@ class SelfAttention(Attention):
|
|||
device=device,
|
||||
dtype=dtype,
|
||||
)
|
||||
self.insert(0, Parallel(Identity(), Identity(), Identity()))
|
||||
self.insert(
|
||||
index=0,
|
||||
module=Parallel(
|
||||
Identity(), # Query projection's input
|
||||
Identity(), # Key projection's input
|
||||
Identity(), # Value projection's input
|
||||
),
|
||||
)
|
||||
|
||||
|
||||
class SelfAttention2d(SelfAttention):
|
||||
"""Multi-Head 2D Self-Attention layer.
|
||||
|
||||
Note: This Module simply chains
|
||||
- a [`Lambda`][refiners.fluxion.layers.chain.Lambda] layer,
|
||||
which transforms the input Tensor into a sequence
|
||||
- a [`SelfAttention`][refiners.fluxion.layers.attentions.SelfAttention] layer
|
||||
- a [`Lambda`][refiners.fluxion.layers.chain.Lambda] layer,
|
||||
which transforms the output sequence into a 2D Tensor
|
||||
|
||||
Receives:
|
||||
(Float[Tensor, "batch channels height width"]):
|
||||
|
||||
Returns:
|
||||
(Float[Tensor, "batch channels height width"]):
|
||||
|
||||
Example:
|
||||
```py
|
||||
self_attention = fl.SelfAttention2d(channels=128, num_heads=8)
|
||||
|
||||
tensor = torch.randn(2, 128, 64, 64)
|
||||
output = self_attention(tensor)
|
||||
|
||||
assert output.shape == (2, 128, 64, 64)
|
||||
```
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
channels: int,
|
||||
num_heads: int = 1,
|
||||
use_bias: bool = True,
|
||||
is_causal: bool | None = None,
|
||||
is_causal: bool = False,
|
||||
is_optimized: bool = True,
|
||||
device: Device | str | None = None,
|
||||
dtype: DType | None = None,
|
||||
) -> None:
|
||||
"""Initialize the 2D Self-Attention layer.
|
||||
|
||||
Args:
|
||||
channels: The number of channels of the input and output tensors.
|
||||
num_heads: The number of heads to use.
|
||||
use_bias: Whether to use bias in the linear layers.
|
||||
is_causal: Whether to use causal attention.
|
||||
is_optimized: Whether to use optimized attention.
|
||||
device: The device to use.
|
||||
dtype: The dtype to use.
|
||||
"""
|
||||
assert channels % num_heads == 0, f"channels {channels} must be divisible by num_heads {num_heads}"
|
||||
self.channels = channels
|
||||
|
||||
super().__init__(
|
||||
embedding_dim=channels,
|
||||
num_heads=num_heads,
|
||||
|
|
@ -226,21 +443,45 @@ class SelfAttention2d(SelfAttention):
|
|||
device=device,
|
||||
dtype=dtype,
|
||||
)
|
||||
self.insert(0, Lambda(self.tensor_2d_to_sequence))
|
||||
self.append(Lambda(self.sequence_to_tensor_2d))
|
||||
|
||||
self.insert(0, Lambda(self._tensor_2d_to_sequence))
|
||||
self.append(Lambda(self._sequence_to_tensor_2d))
|
||||
|
||||
def init_context(self) -> Contexts:
|
||||
return {"reshape": {"height": None, "width": None}}
|
||||
return {
|
||||
"reshape": {
|
||||
"height": None,
|
||||
"width": None,
|
||||
}
|
||||
}
|
||||
|
||||
def tensor_2d_to_sequence(
|
||||
self, x: Float[Tensor, "batch channels height width"]
|
||||
def _tensor_2d_to_sequence(
|
||||
self,
|
||||
x: Float[Tensor, "batch channels height width"],
|
||||
) -> Float[Tensor, "batch height*width channels"]:
|
||||
"""Transform a 2D Tensor into a sequence.
|
||||
|
||||
The height and width of the input Tensor are stored in the context,
|
||||
so that the output Tensor can be transformed back into a 2D Tensor in the `sequence_to_tensor_2d` method.
|
||||
"""
|
||||
height, width = x.shape[-2:]
|
||||
self.set_context(context="reshape", value={"height": height, "width": width})
|
||||
self.set_context(
|
||||
context="reshape",
|
||||
value={
|
||||
"height": height,
|
||||
"width": width,
|
||||
},
|
||||
)
|
||||
return x.reshape(x.shape[0], x.shape[1], height * width).transpose(1, 2)
|
||||
|
||||
def sequence_to_tensor_2d(
|
||||
self, x: Float[Tensor, "batch sequence_length channels"]
|
||||
def _sequence_to_tensor_2d(
|
||||
self,
|
||||
x: Float[Tensor, "batch sequence_length channels"],
|
||||
) -> Float[Tensor, "batch channels height width"]:
|
||||
"""Transform a sequence into a 2D Tensor.
|
||||
|
||||
The height and width of the output Tensor are retrieved from the context,
|
||||
which was set in the `tensor_2d_to_sequence` method.
|
||||
"""
|
||||
height, width = self.use_context("reshape").values()
|
||||
return x.transpose(1, 2).reshape(x.shape[0], x.shape[2], height, width)
|
||||
|
|
|
|||
Loading…
Reference in a new issue