mirror of
https://github.com/finegrain-ai/refiners.git
synced 2024-11-09 15:02:01 +00:00
README: upgrade hello world
This commit is contained in:
parent
3f54494e04
commit
5d19d14e51
118
README.md
118
README.md
|
|
@ -60,68 +60,122 @@ pytest
|
||||||
|
|
||||||
### Hello World
|
### Hello World
|
||||||
|
|
||||||
Here is how to perform a text-to-image inference using the Stable Diffusion 1.5 foundational model patched with a Pokemon LoRA:
|
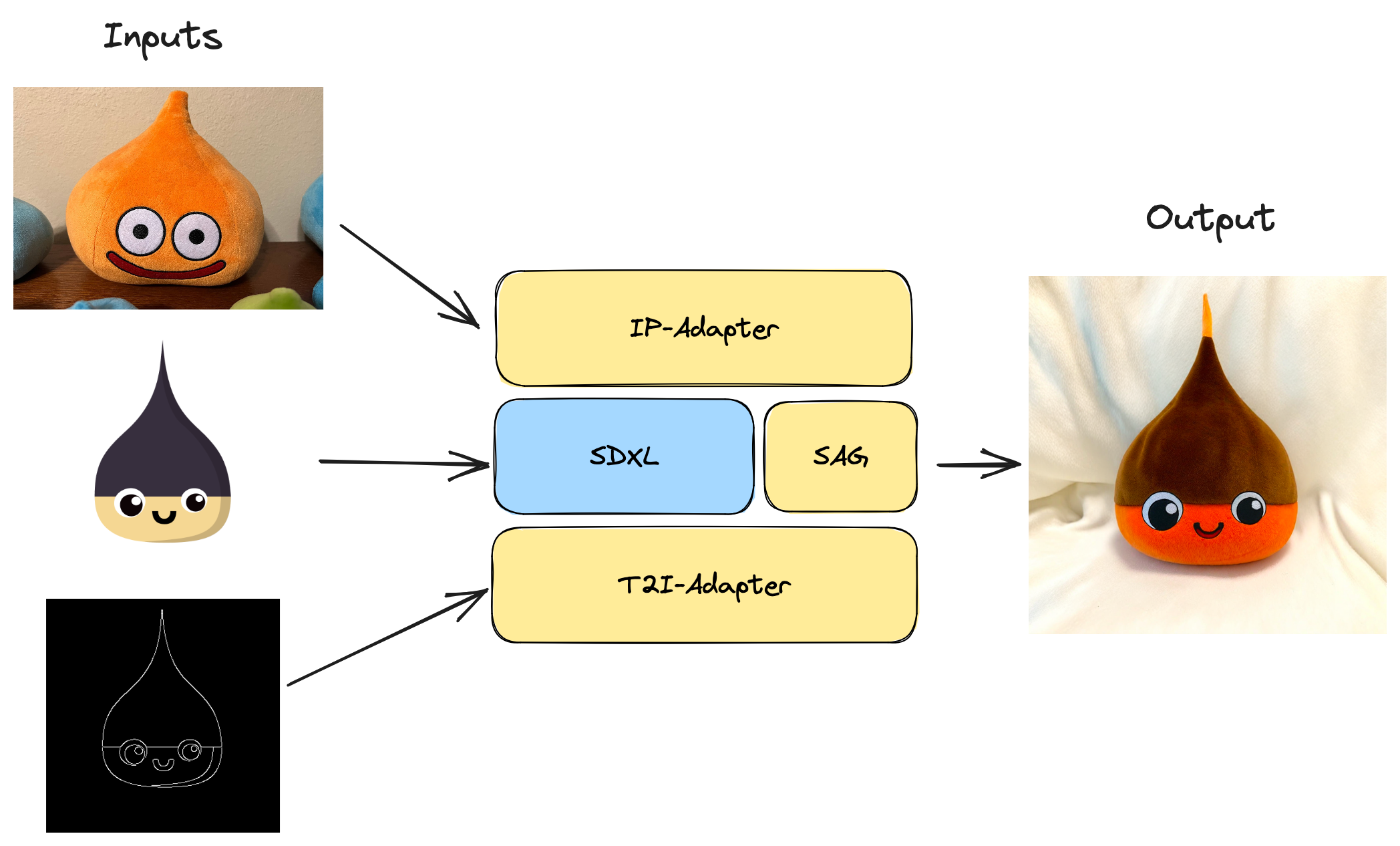
Goal: turn Refiners' mascot into a [Dragon Quest Slime](https://en.wikipedia.org/wiki/Slime_(Dragon_Quest)) plush in a one-shot manner thanks to a powerful combo of adapters:
|
||||||
|
- IP-Adapter: to capture the Slime plush visual appearance into an image prompt (no prompt engineering needed)
|
||||||
|
- T2I-Adapter: to guide the generation with the mascot's geometry
|
||||||
|
- Self-Attention-Guidance (SAG): to increase the sharpness
|
||||||
|
|
||||||
Step 1: prepare the model weights in refiners' format:
|
|
||||||
|
|
||||||
|
**Step 1**: convert SDXL weights to the Refiners' format:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
python scripts/conversion/convert_transformers_clip_text_model.py --to clip.safetensors
|
python scripts/conversion/convert_transformers_clip_text_model.py --from "stabilityai/stable-diffusion-xl-base-1.0" --subfolder2 text_encoder_2 --to clip_text_xl.safetensors --half
|
||||||
python scripts/conversion/convert_diffusers_autoencoder_kl.py --to lda.safetensors
|
python scripts/conversion/convert_diffusers_unet.py --from "stabilityai/stable-diffusion-xl-base-1.0" --to unet_xl.safetensors --half
|
||||||
python scripts/conversion/convert_diffusers_unet.py --to unet.safetensors
|
python scripts/conversion/convert_diffusers_autoencoder_kl.py --from "madebyollin/sdxl-vae-fp16-fix" --subfolder "" --to lda_xl.safetensors --half
|
||||||
```
|
```
|
||||||
|
|
||||||
> Note: this will download the original weights from https://huggingface.co/runwayml/stable-diffusion-v1-5 which takes some time. If you already have this repo cloned locally, use the `--from /path/to/stable-diffusion-v1-5` option instead.
|
> Note: this will download the original weights from https://huggingface.co/ which takes some time. If you already have this repo cloned locally, use the `--from /path/to/stabilityai/stable-diffusion-xl-base-1.0` option instead.
|
||||||
|
|
||||||
Step 2: download and convert a community Pokemon LoRA, e.g. [this one](https://huggingface.co/pcuenq/pokemon-lora)
|
And then convert IP-Adapter and T2I-Adapter weights (note: SAG is parameter-free):
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
curl -LO https://huggingface.co/pcuenq/pokemon-lora/resolve/main/pytorch_lora_weights.bin
|
python scripts/conversion/convert_diffusers_t2i_adapter.py --from "TencentARC/t2i-adapter-canny-sdxl-1.0" --to t2i_canny_xl.safetensors --half
|
||||||
python scripts/conversion/convert_diffusers_lora.py \
|
python scripts/conversion/convert_transformers_clip_image_model.py --from "stabilityai/stable-diffusion-2-1-unclip" --to clip_image.safetensors --half
|
||||||
--from pytorch_lora_weights.bin \
|
curl -LO https://huggingface.co/h94/IP-Adapter/resolve/main/sdxl_models/ip-adapter_sdxl_vit-h.bin
|
||||||
--to pokemon_lora.safetensors
|
python scripts/conversion/convert_diffusers_ip_adapter.py --from ip-adapter_sdxl_vit-h.bin --half
|
||||||
```
|
```
|
||||||
|
|
||||||
Step 3: run inference using the GPU:
|
**Step 2**: download input images:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
curl -O https://raw.githubusercontent.com/finegrain-ai/refiners/main/assets/dropy_logo.png
|
||||||
|
curl -O https://raw.githubusercontent.com/finegrain-ai/refiners/main/assets/dropy_canny.png
|
||||||
|
curl -O https://raw.githubusercontent.com/finegrain-ai/refiners/main/assets/dragon_quest_slime.jpg
|
||||||
|
```
|
||||||
|
|
||||||
|
**Step 3**: generate an image using the GPU:
|
||||||
|
|
||||||
```python
|
```python
|
||||||
from refiners.foundationals.latent_diffusion import StableDiffusion_1
|
|
||||||
from refiners.foundationals.latent_diffusion.lora import SD1LoraAdapter
|
|
||||||
from refiners.fluxion.utils import load_from_safetensors, manual_seed
|
|
||||||
import torch
|
import torch
|
||||||
|
|
||||||
|
from PIL import Image
|
||||||
|
|
||||||
sd15 = StableDiffusion_1(device="cuda")
|
from refiners.foundationals.latent_diffusion.stable_diffusion_xl import StableDiffusion_XL
|
||||||
sd15.clip_text_encoder.load_from_safetensors("clip.safetensors")
|
from refiners.foundationals.latent_diffusion import SDXLIPAdapter, SDXLT2IAdapter
|
||||||
sd15.lda.load_from_safetensors("lda.safetensors")
|
from refiners.fluxion.utils import manual_seed, image_to_tensor, load_from_safetensors
|
||||||
sd15.unet.load_from_safetensors("unet.safetensors")
|
|
||||||
|
|
||||||
SD1LoraAdapter.from_safetensors(target=sd15, checkpoint_path="pokemon_lora.safetensors", scale=1.0).inject()
|
# Load inputs
|
||||||
|
init_image = Image.open("dropy_logo.png")
|
||||||
|
image_prompt = Image.open("dragon_quest_slime.jpg")
|
||||||
|
condition_image = Image.open("dropy_canny.png")
|
||||||
|
|
||||||
prompt = "a cute cat"
|
# Load SDXL
|
||||||
|
sdxl = StableDiffusion_XL(device="cuda", dtype=torch.float16)
|
||||||
|
sdxl.clip_text_encoder.load_from_safetensors("clip_text_xl.safetensors")
|
||||||
|
sdxl.lda.load_from_safetensors("lda_xl.safetensors")
|
||||||
|
sdxl.unet.load_from_safetensors("unet_xl.safetensors")
|
||||||
|
|
||||||
|
# Load and inject adapters
|
||||||
|
ip_adapter = SDXLIPAdapter(target=sdxl.unet, weights=load_from_safetensors("ip-adapter_sdxl_vit-h.safetensors"))
|
||||||
|
ip_adapter.clip_image_encoder.load_from_safetensors("clip_image.safetensors")
|
||||||
|
ip_adapter.inject()
|
||||||
|
|
||||||
|
t2i_adapter = SDXLT2IAdapter(
|
||||||
|
target=sdxl.unet, name="canny", weights=load_from_safetensors("t2i_canny_xl.safetensors")
|
||||||
|
).inject()
|
||||||
|
|
||||||
|
# Tune parameters
|
||||||
|
seed = 9752
|
||||||
|
first_step = 1
|
||||||
|
ip_adapter.set_scale(0.85)
|
||||||
|
t2i_adapter.set_scale(0.8)
|
||||||
|
sdxl.set_num_inference_steps(50)
|
||||||
|
sdxl.set_self_attention_guidance(enable=True, scale=0.75)
|
||||||
|
|
||||||
with torch.no_grad():
|
with torch.no_grad():
|
||||||
clip_text_embedding = sd15.compute_clip_text_embedding(prompt)
|
# Note: default text prompts for IP-Adapter
|
||||||
|
clip_text_embedding, pooled_text_embedding = sdxl.compute_clip_text_embedding(
|
||||||
|
text="best quality, high quality", negative_text="monochrome, lowres, bad anatomy, worst quality, low quality"
|
||||||
|
)
|
||||||
|
clip_image_embedding = ip_adapter.compute_clip_image_embedding(ip_adapter.preprocess_image(image_prompt))
|
||||||
|
|
||||||
sd15.set_num_inference_steps(30)
|
negative_text_embedding, conditional_text_embedding = clip_text_embedding.chunk(2)
|
||||||
|
negative_image_embedding, conditional_image_embedding = clip_image_embedding.chunk(2)
|
||||||
|
|
||||||
manual_seed(2)
|
clip_text_embedding = torch.cat(
|
||||||
x = torch.randn(1, 4, 64, 64, device=sd15.device)
|
(
|
||||||
|
torch.cat([negative_text_embedding, negative_image_embedding], dim=1),
|
||||||
|
torch.cat([conditional_text_embedding, conditional_image_embedding], dim=1),
|
||||||
|
)
|
||||||
|
)
|
||||||
|
time_ids = sdxl.default_time_ids
|
||||||
|
|
||||||
with torch.no_grad():
|
condition = image_to_tensor(condition_image.convert("RGB"), device=sdxl.device, dtype=sdxl.dtype)
|
||||||
for step in sd15.steps:
|
t2i_adapter.set_condition_features(features=t2i_adapter.compute_condition_features(condition))
|
||||||
x = sd15(
|
|
||||||
|
manual_seed(seed=seed)
|
||||||
|
x = sdxl.init_latents(size=(1024, 1024), init_image=init_image, first_step=first_step).to(
|
||||||
|
device=sdxl.device, dtype=sdxl.dtype
|
||||||
|
)
|
||||||
|
|
||||||
|
for step in sdxl.steps[first_step:]:
|
||||||
|
x = sdxl(
|
||||||
x,
|
x,
|
||||||
step=step,
|
step=step,
|
||||||
clip_text_embedding=clip_text_embedding,
|
clip_text_embedding=clip_text_embedding,
|
||||||
condition_scale=7.5,
|
pooled_text_embedding=pooled_text_embedding,
|
||||||
|
time_ids=time_ids,
|
||||||
)
|
)
|
||||||
predicted_image = sd15.lda.decode_latents(x)
|
predicted_image = sdxl.lda.decode_latents(x=x)
|
||||||
predicted_image.save("pokemon_cat.png")
|
|
||||||
|
predicted_image.save("output.png")
|
||||||
|
print("done: see output.png")
|
||||||
```
|
```
|
||||||
|
|
||||||
You should get:
|
You should get:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
### Training
|
### Training
|
||||||
|
|
||||||
|
|
|
||||||
3
assets/README.md
Normal file
3
assets/README.md
Normal file
|
|
@ -0,0 +1,3 @@
|
||||||
|
# Note about this data
|
||||||
|
|
||||||
|
- `dragon_quest_slime.jpg`: from [My Dragon Quest Slime Plush Collection ](https://www.reddit.com/r/dragonquest/comments/x2q2y3/my_dragon_quest_slime_plush_collection/) by [RetroGamer489](https://www.reddit.com/user/RetroGamer489/)
|
||||||
BIN
assets/dragon_quest_slime.jpg
Normal file
BIN
assets/dragon_quest_slime.jpg
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 244 KiB |
BIN
assets/dropy_canny.png
Normal file
BIN
assets/dropy_canny.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 39 KiB |
BIN
assets/dropy_logo.png
Normal file
BIN
assets/dropy_logo.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 14 KiB |
BIN
assets/dropy_slime_9752.png
Normal file
BIN
assets/dropy_slime_9752.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 1.5 MiB |
BIN
assets/hello_world_overview.png
Normal file
BIN
assets/hello_world_overview.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 1 MiB |
Loading…
Reference in a new issue