Attention(
embedding_dim: int,
num_heads: int = 1,
key_embedding_dim: int | None = None,
value_embedding_dim: int | None = None,
inner_dim: int | None = None,
use_bias: bool = True,
is_causal: bool = False,
is_optimized: bool = True,
device: device | str | None = None,
dtype: dtype | None = None,
)
Bases: Chain
Multi-Head Attention layer.
See [arXiv:1706.03762] Attention Is All You Need (Figure 2) for more details
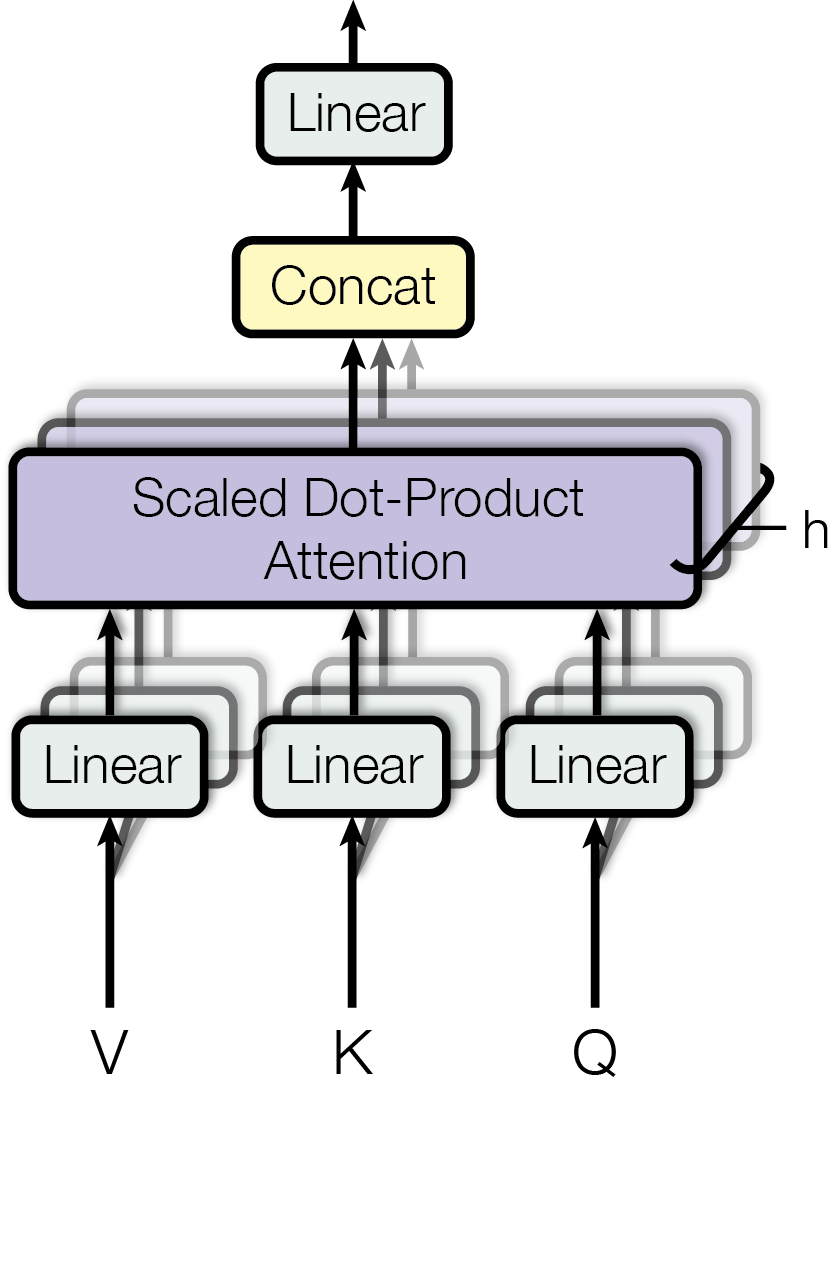
This layer simply chains
- a
Distributelayer, containing 3Linearlayers, which transforms the 3 inputs into Query, Key and Value - a
ScaledDotProductAttentionlayer - a
Linearlayer, which projects the output of theScaledDotProductAttentionlayer
Receives:
| Name | Type | Description |
|---|---|---|
Query |
Float[Tensor, 'batch sequence_length embedding_dim']
|
|
Key |
Float[Tensor, 'batch sequence_length embedding_dim']
|
|
Value |
Float[Tensor, 'batch sequence_length embedding_dim']
|
|
Returns:
| Type | Description |
|---|---|
Float[Tensor, 'batch sequence_length embedding_dim']
|
|
Example
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
embedding_dim
|
int
|
The embedding dimension of the input and output tensors. |
required |
num_heads
|
int
|
The number of heads to use. |
1
|
key_embedding_dim
|
int | None
|
The embedding dimension of the key tensor. |
None
|
value_embedding_dim
|
int | None
|
The embedding dimension of the value tensor. |
None
|
inner_dim
|
int | None
|
The inner dimension of the linear layers. |
None
|
use_bias
|
bool
|
Whether to use bias in the linear layers. |
True
|
is_causal
|
bool
|
Whether to use causal attention. |
False
|
is_optimized
|
bool
|
Whether to use optimized attention. |
True
|
device
|
device | str | None
|
The device to use. |
None
|
dtype
|
dtype | None
|
The dtype to use. |
None
|
Source code in src/refiners/fluxion/layers/attentions.py
240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 | |
Breakpoint(vscode: bool = True)
Bases: ContextModule
Breakpoint layer.
This layer pauses the execution when encountered, and opens a debugger.
Source code in src/refiners/fluxion/layers/chain.py
Bases: ContextModule
Chain layer.
This layer is the main building block of Fluxion.
It is used to compose other layers in a sequential manner.
Similarly to torch.nn.Sequential,
it calls each of its sub-layers in order, chaining their outputs as inputs to the next sublayer.
However, it also provides additional methods to manipulate its sub-layers and their context.
Example
Source code in src/refiners/fluxion/layers/chain.py
append(module: Module) -> None
Append a new module to the chain.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
module
|
Module
|
The module to append. |
required |
ensure_find(layer_type: type[T]) -> T
Walk the Chain's sub-module tree and return the first layer of the given type.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
layer_type
|
type[T]
|
The type of layer to find. |
required |
Returns:
| Type | Description |
|---|---|
T
|
The first module of the given layer_type. |
Raises:
| Type | Description |
|---|---|
AssertionError
|
If the module doesn't exist. |
Source code in src/refiners/fluxion/layers/chain.py
Walk the Chain's sub-module tree and return the parent of the given module.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
module
|
Module
|
The module whose parent to find. |
required |
Returns:
| Type | Description |
|---|---|
Chain
|
The parent of the given module. |
Raises:
| Type | Description |
|---|---|
AssertionError
|
If the module doesn't exist. |
Source code in src/refiners/fluxion/layers/chain.py
find(layer_type: type[T]) -> T | None
Walk the Chain's sub-module tree and return the first layer of the given type.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
layer_type
|
type[T]
|
The type of layer to find. |
required |
Returns:
| Type | Description |
|---|---|
T | None
|
The first module of the given layer_type, or None if it doesn't exist. |
Source code in src/refiners/fluxion/layers/chain.py
Walk the Chain's sub-module tree and return the parent of the given module.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
module
|
Module
|
The module whose parent to find. |
required |
Returns:
| Type | Description |
|---|---|
Chain | None
|
The parent of the given module, or None if it doesn't exist. |
Source code in src/refiners/fluxion/layers/chain.py
Initialize the context provider with some default values.
This method is called when the Chain is created, and when it is reset. This method may be overridden by subclasses to provide default values for the context provider.
Source code in src/refiners/fluxion/layers/chain.py
Insert a new module in the chain.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
index
|
int
|
The index at which to insert the module. |
required |
module
|
Module
|
The module to insert. |
required |
Raises:
| Type | Description |
|---|---|
IndexError
|
If the index is out of range. |
Source code in src/refiners/fluxion/layers/chain.py
Insert a new module in the chain, right after the first module of the given type.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
module_type
|
type[Module]
|
The type of module to insert after. |
required |
new_module
|
Module
|
The module to insert. |
required |
Raises:
| Type | Description |
|---|---|
ValueError
|
If no module of the given type exists in the chain. |
Source code in src/refiners/fluxion/layers/chain.py
Insert a new module in the chain, right before the first module of the given type.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
module_type
|
type[Module]
|
The type of module to insert before. |
required |
new_module
|
Module
|
The module to insert. |
required |
Raises:
| Type | Description |
|---|---|
ValueError
|
If no module of the given type exists in the chain. |
Source code in src/refiners/fluxion/layers/chain.py
Access a layer of the Chain given its type.
Example
# same as my_chain["Linear_2"], asserts it is a Linear
my_chain.layer("Linear_2", fl.Linear)
# same as my_chain[3], asserts it is a Linear
my_chain.layer(3, fl.Linear)
# probably won't work
my_chain.layer("Conv2d", fl.Linear)
# same as my_chain["foo"][42]["bar"],
# assuming bar is a MyType and all parents are Chains
my_chain.layer(("foo", 42, "bar"), fl.MyType)
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
key
|
str | int | Sequence[str | int]
|
The key or path of the layer. |
required |
layer_type
|
type[T]
|
The type of the layer. |
Module
|
Yields:
| Type | Description |
|---|---|
T
|
The layer. |
Raises:
| Type | Description |
|---|---|
AssertionError
|
If the layer doesn't exist or the type is invalid. |
Source code in src/refiners/fluxion/layers/chain.py
Walk the Chain's sub-module tree and yield each layer of the given type.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
layer_type
|
type[T]
|
The type of layer to yield. |
required |
recurse
|
bool
|
Whether to recurse into sub-Chains. |
False
|
Yields:
| Type | Description |
|---|---|
T
|
Each module of the given layer_type. |
Source code in src/refiners/fluxion/layers/chain.py
Pop a module from the chain at the given index.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
index
|
int
|
The index of the module to pop. |
-1
|
Returns:
| Type | Description |
|---|---|
Module
|
The popped module. |
Raises:
| Type | Description |
|---|---|
IndexError
|
If the index is out of range. |
Source code in src/refiners/fluxion/layers/chain.py
remove(module: Module) -> None
Remove a module from the chain.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
module
|
Module
|
The module to remove. |
required |
Raises:
| Type | Description |
|---|---|
ValueError
|
If the module is not in the chain. |
Source code in src/refiners/fluxion/layers/chain.py
Replace a module in the chain with a new module.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
old_module
|
Module
|
The module to replace. |
required |
new_module
|
Module
|
The module to replace with. |
required |
old_module_parent
|
Chain | None
|
The parent of the old module. If None, the old module is orphanized. |
None
|
Raises:
| Type | Description |
|---|---|
ValueError
|
If the module is not in the chain. |
Source code in src/refiners/fluxion/layers/chain.py
Copy the structure of the Chain tree.
This method returns a recursive copy of the Chain tree where all inner nodes (instances of Chain and its subclasses) are duplicated and all leaves (regular Modules) are not.
Such copies can be adapted without disrupting the base model, but do not require extra GPU memory since the weights are in the leaves and hence not copied.
Source code in src/refiners/fluxion/layers/chain.py
walk(
predicate: (
type[T] | Callable[[Module, Chain], bool] | None
) = None,
recurse: bool = False,
) -> (
Iterator[tuple[T, Chain]]
| Iterator[tuple[Module, Chain]]
)
Walk the Chain's sub-module tree and yield each module that matches the predicate.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
predicate
|
type[T] | Callable[[Module, Chain], bool] | None
|
The predicate to match. |
None
|
recurse
|
bool
|
Whether to recurse into sub-Chains. |
False
|
Yields:
| Type | Description |
|---|---|
Iterator[tuple[T, Chain]] | Iterator[tuple[Module, Chain]]
|
Each module that matches the predicate. |
Source code in src/refiners/fluxion/layers/chain.py
Bases: Chain
Concatenation layer.
This layer calls its sub-modules in parallel with the same inputs, and returns the concatenation of their outputs.
Example
Source code in src/refiners/fluxion/layers/chain.py
Bases: Module
A module containing a ContextProvider.
Source code in src/refiners/fluxion/layers/module.py
property
¶
ensure_parent: Chain
Return the module's parent, or raise an error if module is an orphan.
Get the path of the module in the chain.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
parent
|
Chain | None
|
The parent of the module in the chain. |
None
|
top
|
Module | None
|
The top module of the chain. If None, the path will be relative to the root of the chain. |
None
|
Source code in src/refiners/fluxion/layers/module.py
Conv2d(
in_channels: int,
out_channels: int,
kernel_size: int | tuple[int, int],
stride: int | tuple[int, int] = (1, 1),
padding: int | tuple[int, int] | str = (0, 0),
groups: int = 1,
use_bias: bool = True,
dilation: int | tuple[int, int] = (1, 1),
padding_mode: str = "zeros",
device: device | str | None = None,
dtype: dtype | None = None,
)
Bases: Conv2d, WeightedModule
2D Convolutional layer.
This layer wraps torch.nn.Conv2d.
Receives:
| Type | Description |
|---|---|
Real[Tensor, 'batch in_channels in_height in_width']
|
|
Returns:
| Type | Description |
|---|---|
Real[Tensor, 'batch out_channels out_height out_width']
|
|
Example
Source code in src/refiners/fluxion/layers/conv.py
ConvTranspose2d(
in_channels: int,
out_channels: int,
kernel_size: int | tuple[int, int],
stride: int | tuple[int, int] = 1,
padding: int | tuple[int, int] = 0,
output_padding: int | tuple[int, int] = 0,
groups: int = 1,
use_bias: bool = True,
dilation: int | tuple[int, int] = 1,
padding_mode: str = "zeros",
device: device | str | None = None,
dtype: dtype | None = None,
)
Bases: ConvTranspose2d, WeightedModule
2D Transposed Convolutional layer.
This layer wraps torch.nn.ConvTranspose2d.
Receives:
| Type | Description |
|---|---|
Real[Tensor, 'batch in_channels in_height in_width']
|
|
Returns:
| Type | Description |
|---|---|
Real[Tensor, 'batch out_channels out_height out_width']
|
|
Example
Source code in src/refiners/fluxion/layers/conv.py
Bases: ContextModule
A Converter class that adjusts tensor properties based on a parent module's settings.
This class inherits from ContextModule
and provides functionality to adjust the device and dtype
of input tensor(s) to match the parent module's attributes.
Note
Ensure the parent module has device and dtype attributes if set_device or set_dtype are set to True.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
set_device
|
bool
|
If True, matches the device of the input tensor(s) to the parent's device. |
True
|
set_dtype
|
bool
|
If True, matches the dtype of the input tensor(s) to the parent's dtype. |
True
|
Source code in src/refiners/fluxion/layers/converter.py
Bases: Chain
Distribute layer.
This layer calls its sub-modules in parallel with their respective input, and returns a tuple of their outputs.
Example
Source code in src/refiners/fluxion/layers/chain.py
Downsample(
channels: int,
scale_factor: int,
padding: int = 0,
register_shape: bool = True,
device: device | str | None = None,
dtype: dtype | None = None,
)
Bases: Chain
Downsample layer.
This layer downsamples the input by the given scale factor.
Raises:
| Type | Description |
|---|---|
RuntimeError
|
If the context sampling is not set or if the context does not contain a list. |
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
channels
|
int
|
The number of input and output channels. |
required |
scale_factor
|
int
|
The factor by which to downsample the input. |
required |
padding
|
int
|
The amount of zero-padding added to both sides of the input. |
0
|
register_shape
|
bool
|
If True, registers the input shape in the context. |
True
|
device
|
device | str | None
|
The device to use for the convolutional layer. |
None
|
dtype
|
dtype | None
|
The dtype to use for the convolutional layer. |
None
|
Source code in src/refiners/fluxion/layers/sampling.py
Embedding(
num_embeddings: int,
embedding_dim: int,
device: device | str | None = None,
dtype: dtype | None = None,
)
Bases: Embedding, WeightedModule
Embedding layer.
This layer wraps torch.nn.Embedding.
Receives:
| Type | Description |
|---|---|
Int[Tensor, 'batch length']
|
|
Returns:
| Type | Description |
|---|---|
Float[Tensor, 'batch length embedding_dim']
|
|
Example
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
num_embeddings
|
int
|
The number of embeddings. |
required |
embedding_dim
|
int
|
The dimension of the embeddings. |
required |
device
|
device | str | None
|
The device to use for the embedding layer. |
None
|
dtype
|
dtype | None
|
The dtype to use for the embedding layer. |
None
|
Source code in src/refiners/fluxion/layers/embedding.py
Bases: Module
Flatten operation layer.
This layer flattens the input tensor between the given dimensions.
See also torch.flatten.
Example
Source code in src/refiners/fluxion/layers/basics.py
GLU(activation: Activation)
Bases: Activation
Gated Linear Unit activation function.
See [arXiv:2002.05202] GLU Variants Improve Transformer for more details.
Example
Source code in src/refiners/fluxion/layers/activations.py
GeLU(approximation: GeLUApproximation = NONE)
Bases: Activation
Gaussian Error Linear Unit activation function.
This activation can be quite expensive to compute, a few approximations are available,
see GeLUApproximation.
See [arXiv:1606.08415] Gaussian Error Linear Units for more details.
Source code in src/refiners/fluxion/layers/activations.py
Bases: Enum
Approximation methods for the Gaussian Error Linear Unit activation function.
Attributes:
| Name | Type | Description |
|---|---|---|
NONE |
No approximation, use the original formula. |
|
TANH |
Use the tanh approximation. |
|
SIGMOID |
Use the sigmoid approximation. |
GetArg(index: int)
Bases: Module
GetArg operation layer.
This layer returns the nth tensor of the input arguments.
Example
Source code in src/refiners/fluxion/layers/basics.py
GroupNorm(
channels: int,
num_groups: int,
eps: float = 1e-05,
device: device | str | None = None,
dtype: dtype | None = None,
)
Bases: GroupNorm, WeightedModule
Group Normalization layer.
This layer wraps torch.nn.GroupNorm.
Receives:
| Type | Description |
|---|---|
Float[Tensor, 'batch channels *normalized_shape']
|
|
Returns:
| Type | Description |
|---|---|
Float[Tensor, 'batch channels *normalized_shape']
|
|
Example
Source code in src/refiners/fluxion/layers/norm.py
Bases: Module
Identity operator layer.
This layer simply returns the input tensor.
Example
Source code in src/refiners/fluxion/layers/basics.py
InstanceNorm2d(
num_features: int,
eps: float = 1e-05,
device: device | str | None = None,
dtype: dtype | None = None,
)
Bases: InstanceNorm2d, Module
Instance Normalization layer.
This layer wraps torch.nn.InstanceNorm2d.
Receives:
| Type | Description |
|---|---|
Float[Tensor, 'batch channels height width']
|
|
Returns:
| Type | Description |
|---|---|
Float[Tensor, 'batch channels height width']
|
|
Source code in src/refiners/fluxion/layers/norm.py
Bases: Module
Interpolate layer.
This layer wraps torch.nn.functional.interpolate.
Source code in src/refiners/fluxion/layers/sampling.py
LayerNorm(
normalized_shape: int | list[int],
eps: float = 1e-05,
device: device | str | None = None,
dtype: dtype | None = None,
)
Bases: LayerNorm, WeightedModule
Layer Normalization layer.
This layer wraps torch.nn.LayerNorm.
Receives:
| Type | Description |
|---|---|
Float[Tensor, batch * normalized_shape]
|
|
Returns:
| Type | Description |
|---|---|
Float[Tensor, batch * normalized_shape]
|
|
Example
Source code in src/refiners/fluxion/layers/norm.py
LayerNorm2d(
channels: int,
eps: float = 1e-06,
device: device | str | None = None,
dtype: dtype | None = None,
)
Bases: WeightedModule
2D Layer Normalization layer.
This layer applies Layer Normalization along the 2nd dimension of a 4D tensor.
Receives:
| Type | Description |
|---|---|
Float[Tensor, 'batch channels height width']
|
|
Returns:
| Type | Description |
|---|---|
Float[Tensor, 'batch channels height width']
|
|
Source code in src/refiners/fluxion/layers/norm.py
Linear(
in_features: int,
out_features: int,
bias: bool = True,
device: device | str | None = None,
dtype: dtype | None = None,
)
Bases: Linear, WeightedModule
Linear layer.
This layer wraps torch.nn.Linear.
Receives:
| Name | Type | Description |
|---|---|---|
Input |
Float[Tensor, 'batch in_features']
|
|
Returns:
| Name | Type | Description |
|---|---|---|
Output |
Float[Tensor, 'batch out_features']
|
|
Example
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
in_features
|
int
|
The number of input features. |
required |
out_features
|
int
|
The number of output features. |
required |
bias
|
bool
|
If True, adds a learnable bias to the output. |
True
|
device
|
device | str | None
|
The device to use for the linear layer. |
None
|
dtype
|
dtype | None
|
The dtype to use for the linear layer. |
None
|
Source code in src/refiners/fluxion/layers/linear.py
Bases: Chain
Matrix multiplication layer.
This layer returns the matrix multiplication of the outputs of its two sub-modules.
Example
Source code in src/refiners/fluxion/layers/chain.py
MaxPool1d(
kernel_size: int,
stride: int | None = None,
padding: int = 0,
dilation: int = 1,
return_indices: bool = False,
ceil_mode: bool = False,
)
MaxPool1d layer.
This layer wraps torch.nn.MaxPool1d.
Receives:
| Type | Description |
|---|---|
Float[Tensor, 'batch channels in_length']
|
|
Returns:
| Type | Description |
|---|---|
Float[Tensor, 'batch channels out_length']
|
|
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
kernel_size
|
int
|
The size of the sliding window. |
required |
stride
|
int | None
|
The stride of the sliding window. |
None
|
padding
|
int
|
The amount of zero-padding added to both sides of the input. |
0
|
dilation
|
int
|
The spacing between kernel elements. |
1
|
return_indices
|
bool
|
If True, returns the max indices along with the outputs. |
False
|
ceil_mode
|
bool
|
If True, uses ceil instead of floor to compute the output shape. |
False
|
Source code in src/refiners/fluxion/layers/maxpool.py
MaxPool2d(
kernel_size: int | tuple[int, int],
stride: int | tuple[int, int] | None = None,
padding: int | tuple[int, int] = (0, 0),
dilation: int | tuple[int, int] = (1, 1),
return_indices: bool = False,
ceil_mode: bool = False,
)
MaxPool2d layer.
This layer wraps torch.nn.MaxPool2d.
Receives:
| Type | Description |
|---|---|
Float[Tensor, 'batch channels in_height in_width']
|
|
Returns:
| Type | Description |
|---|---|
Float[Tensor, 'batch channels out_height out_width']
|
|
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
kernel_size
|
int | tuple[int, int]
|
The size of the sliding window. |
required |
stride
|
int | tuple[int, int] | None
|
The stride of the sliding window. |
None
|
padding
|
int | tuple[int, int]
|
The amount of zero-padding added to both sides of the input. |
(0, 0)
|
dilation
|
int | tuple[int, int]
|
The spacing between kernel elements. |
(1, 1)
|
return_indices
|
bool
|
If True, returns the max indices along with the outputs. |
False
|
ceil_mode
|
bool
|
If True, uses ceil instead of floor to compute the output shape. |
False
|
Source code in src/refiners/fluxion/layers/maxpool.py
Bases: Module
A wrapper around torch.nn.Module.
Source code in src/refiners/fluxion/layers/module.py
Return a dictionary of basic attributes of the module.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
init_attrs_only
|
bool
|
Whether to only return attributes that are passed to the module's constructor. |
False
|
Source code in src/refiners/fluxion/layers/module.py
Get the path of the module in the chain.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
parent
|
Chain | None
|
The parent of the module in the chain. |
None
|
top
|
Module | None
|
The top module of the chain. If None, the path will be relative to the root of the chain. |
None
|
Source code in src/refiners/fluxion/layers/module.py
Load the module's state from a SafeTensors file.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
tensors_path
|
str | Path
|
The path to the SafeTensors file. |
required |
strict
|
bool
|
Whether to raise an error if the SafeTensors's content doesn't map perfectly to the module's state. |
True
|
Returns:
| Type | Description |
|---|---|
T
|
The module, with its state loaded from the SafeTensors file. |
Source code in src/refiners/fluxion/layers/module.py
Get all the sub-modules of the module.
Returns:
| Type | Description |
|---|---|
None
|
An iterator over all the sub-modules of the module. |
Source code in src/refiners/fluxion/layers/module.py
pretty_print(depth: int = -1) -> None
Print the module in a tree-like format.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
depth
|
int
|
The maximum depth of the tree to print. If negative, the whole tree is printed. |
-1
|
Source code in src/refiners/fluxion/layers/module.py
Move the module to the given device and cast its parameters to the given dtype.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
device
|
device | str | None
|
The device to move the module to. |
None
|
dtype
|
dtype | None
|
The dtype to cast the module's parameters to. |
None
|
Returns:
| Type | Description |
|---|---|
T
|
The module, moved to the given device and cast to the given dtype. |
Source code in src/refiners/fluxion/layers/module.py
MultiLinear(
input_dim: int,
output_dim: int,
inner_dim: int,
num_layers: int,
device: device | str | None = None,
dtype: dtype | None = None,
)
Bases: Chain
Multi-layer linear network.
This layer wraps multiple torch.nn.Linear layers,
with an Activation layer in between.
Receives:
| Name | Type | Description |
|---|---|---|
Input |
Float[Tensor, 'batch input_dim']
|
|
Returns:
| Name | Type | Description |
|---|---|---|
Output |
Float[Tensor, 'batch output_dim']
|
|
Example
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
input_dim
|
int
|
The input dimension of the first linear layer. |
required |
output_dim
|
int
|
The output dimension of the last linear layer. |
required |
inner_dim
|
int
|
The output dimension of the inner linear layers. |
required |
num_layers
|
int
|
The number of linear layers. |
required |
device
|
device | str | None
|
The device to use for the linear layers. |
None
|
dtype
|
dtype | None
|
The dtype to use for the linear layers. |
None
|
Source code in src/refiners/fluxion/layers/linear.py
Bases: Module
Multiply operator layer.
This layer scales and shifts the input tensor by the given scale and bias.
Example
Source code in src/refiners/fluxion/layers/basics.py
Bases: Chain
Parallel layer.
This layer calls its sub-modules in parallel with the same inputs, and returns a tuple of their outputs.
Example
Source code in src/refiners/fluxion/layers/chain.py
Parameter(
*dims: int,
requires_grad: bool = True,
device: device | str | None = None,
dtype: dtype | None = None
)
Bases: WeightedModule
Parameter layer.
This layer simple wraps a PyTorch Parameter.
When called, it simply returns the Parameter Tensor.
Attributes:
| Name | Type | Description |
|---|---|---|
weight |
Parameter
|
The parameter Tensor. |
Source code in src/refiners/fluxion/layers/basics.py
Bases: Chain
Passthrough layer.
This layer call its sub-modules sequentially, and returns its original inputs,
like an Identity layer.
Example
Source code in src/refiners/fluxion/layers/chain.py
Permute(*dims: int)
Bases: Module
Permute operation layer.
This layer permutes the input tensor according to the given dimensions.
See also torch.permute.
Example
Source code in src/refiners/fluxion/layers/basics.py
PixelUnshuffle(downscale_factor: int)
Bases: PixelUnshuffle, Module
Pixel Unshuffle layer.
This layer wraps torch.nn.PixelUnshuffle.
Receives:
| Type | Description |
|---|---|
Float[Tensor, 'batch in_channels in_height in_width']
|
|
Returns:
| Type | Description |
|---|---|
Float[Tensor, 'batch out_channels out_height out_width']
|
|
Source code in src/refiners/fluxion/layers/pixelshuffle.py
Bases: Activation
Rectified Linear Unit activation function.
See Rectified Linear Units Improve Restricted Boltzmann Machines and Cognitron: A self-organizing multilayered neural network
Example
Source code in src/refiners/fluxion/layers/activations.py
ReflectionPad2d(padding: int)
Bases: ReflectionPad2d, Module
Reflection padding layer.
This layer wraps torch.nn.ReflectionPad2d.
Receives:
| Type | Description |
|---|---|
Float[Tensor, 'batch channels in_height in_width']
|
|
Returns:
| Type | Description |
|---|---|
Float[Tensor, 'batch channels out_height out_width']
|
|
Source code in src/refiners/fluxion/layers/padding.py
Reshape(*shape: int)
Bases: Module
Reshape operation layer.
This layer reshapes the input tensor to a specific shape (which must be compatible with the original shape). See also torch.reshape.
Warning
The first dimension (batch dimension) is forcefully preserved.
Example
Source code in src/refiners/fluxion/layers/basics.py
Bases: Chain
Residual layer.
This layer calls its sub-modules sequentially, and adds the original input to the output.
Example
Source code in src/refiners/fluxion/layers/chain.py
ScaledDotProductAttention(
num_heads: int = 1,
is_causal: bool = False,
is_optimized: bool = True,
slice_size: int | None = None,
)
Bases: Module
Scaled Dot Product Attention.
See [arXiv:1706.03762] Attention Is All You Need (Figure 2) for more details
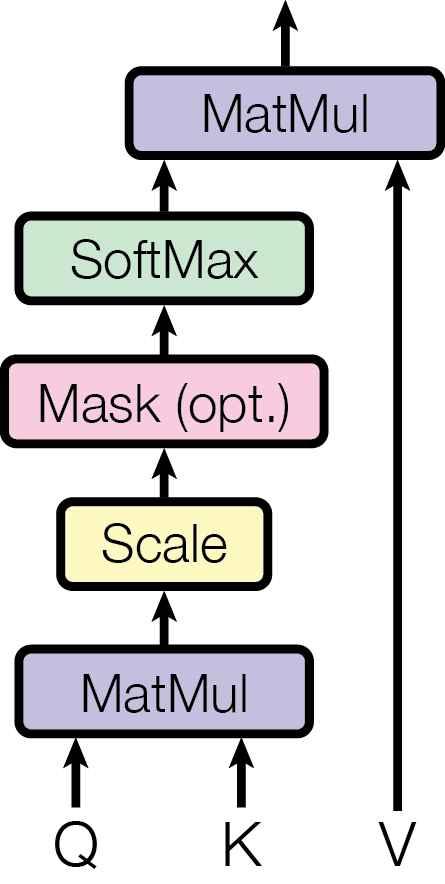
Note
This layer simply wraps scaled_dot_product_attention inside an fl.Module.
Receives:
| Name | Type | Description |
|---|---|---|
Query |
Float[Tensor, 'batch num_queries embedding_dim']
|
|
Key |
Float[Tensor, 'batch num_keys embedding_dim']
|
|
Value |
Float[Tensor, 'batch num_values embedding_dim']
|
|
Returns:
| Type | Description |
|---|---|
Float[Tensor, 'batch num_queries embedding_dim']
|
|
Example
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
num_heads
|
int
|
The number of heads to use. |
1
|
is_causal
|
bool
|
Whether to use causal attention. |
False
|
is_optimized
|
bool
|
Whether to use optimized attention. |
True
|
slice_size
|
int | None
|
The slice size to use for the optimized attention. |
None
|
Source code in src/refiners/fluxion/layers/attentions.py
SelfAttention(
embedding_dim: int,
inner_dim: int | None = None,
num_heads: int = 1,
use_bias: bool = True,
is_causal: bool = False,
is_optimized: bool = True,
device: device | str | None = None,
dtype: dtype | None = None,
)
Bases: Attention
Multi-Head Self-Attention layer.
This layer simply chains
Receives:
| Type | Description |
|---|---|
Float[Tensor, 'batch sequence_length embedding_dim']
|
|
Returns:
| Type | Description |
|---|---|
Float[Tensor, 'batch sequence_length embedding_dim']
|
|
Example
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
embedding_dim
|
int
|
The embedding dimension of the input and output tensors. |
required |
inner_dim
|
int | None
|
The inner dimension of the linear layers. |
None
|
num_heads
|
int
|
The number of heads to use. |
1
|
use_bias
|
bool
|
Whether to use bias in the linear layers. |
True
|
is_causal
|
bool
|
Whether to use causal attention. |
False
|
is_optimized
|
bool
|
Whether to use optimized attention. |
True
|
device
|
device | str | None
|
The device to use. |
None
|
dtype
|
dtype | None
|
The dtype to use. |
None
|
Source code in src/refiners/fluxion/layers/attentions.py
SelfAttention2d(
channels: int,
num_heads: int = 1,
use_bias: bool = True,
is_causal: bool = False,
is_optimized: bool = True,
device: device | str | None = None,
dtype: dtype | None = None,
)
Bases: SelfAttention
Multi-Head 2D Self-Attention layer.
This Module simply chains
- a
Lambdalayer, which transforms the input Tensor into a sequence - a
SelfAttentionlayer - a
Lambdalayer, which transforms the output sequence into a 2D Tensor
Receives:
| Type | Description |
|---|---|
Float[Tensor, 'batch channels height width']
|
|
Returns:
| Type | Description |
|---|---|
Float[Tensor, 'batch channels height width']
|
|
Example
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
channels
|
int
|
The number of channels of the input and output tensors. |
required |
num_heads
|
int
|
The number of heads to use. |
1
|
use_bias
|
bool
|
Whether to use bias in the linear layers. |
True
|
is_causal
|
bool
|
Whether to use causal attention. |
False
|
is_optimized
|
bool
|
Whether to use optimized attention. |
True
|
device
|
device | str | None
|
The device to use. |
None
|
dtype
|
dtype | None
|
The dtype to use. |
None
|
Source code in src/refiners/fluxion/layers/attentions.py
Bases: ContextModule
SetContext layer.
This layer writes to the ContextProvider
of its parent Chain.
When called (without a callback), it will
- Update the context with the given key and the input value
- Return the input value
When called (with a callback), it will
- Call the callback with the current value and the input value (the callback may update the context with a new value, or not)
- Return the input value
Warning
The context needs to already exist in the ContextProvider
Source code in src/refiners/fluxion/layers/chain.py
Bases: Activation
Sigmoid Linear Unit activation function.
See [arXiv:1702.03118] Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforcement Learning for more details.
Source code in src/refiners/fluxion/layers/activations.py
Bases: Activation
Sigmoid activation function.
Source code in src/refiners/fluxion/layers/activations.py
Bases: Module
Slicing operation layer.
This layer slices the input tensor at the given dimension between the given start and end indices.
See also torch.index_select.
Example
Source code in src/refiners/fluxion/layers/basics.py
Squeeze(dim: int)
Bases: Module
Squeeze operation layer.
This layer squeezes the input tensor at the given dimension.
See also torch.squeeze.
Example
Source code in src/refiners/fluxion/layers/basics.py
Bases: Chain
Summation layer.
This layer calls its sub-modules in parallel with the same inputs, and returns the sum of their outputs.
Example
Source code in src/refiners/fluxion/layers/chain.py
Bases: Module
Transpose operation layer.
This layer transposes the input tensor between the two given dimensions.
See also torch.transpose.
Example
Source code in src/refiners/fluxion/layers/basics.py
Unflatten(dim: int)
Bases: Module
Unflatten operation layer.
This layer unflattens the input tensor at the given dimension with the given sizes.
See also torch.unflatten.
Example
Source code in src/refiners/fluxion/layers/basics.py
Unsqueeze(dim: int)
Bases: Module
Unsqueeze operation layer.
This layer unsqueezes the input tensor at the given dimension.
See also torch.unsqueeze.
Example
Source code in src/refiners/fluxion/layers/basics.py
Upsample(
channels: int,
upsample_factor: int | None = None,
device: device | str | None = None,
dtype: dtype | None = None,
)
Bases: Chain
Upsample layer.
This layer upsamples the input by the given scale factor.
Raises:
| Type | Description |
|---|---|
RuntimeError
|
If the context sampling is not set or if the context is empty. |
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
channels
|
int
|
The number of input and output channels. |
required |
upsample_factor
|
int | None
|
The factor by which to upsample the input. If None, the input shape is taken from the context. |
None
|
device
|
device | str | None
|
The device to use for the convolutional layer. |
None
|
dtype
|
dtype | None
|
The dtype to use for the convolutional layer. |
None
|
Source code in src/refiners/fluxion/layers/sampling.py
Bases: ContextModule
UseContext layer.
This layer reads from the ContextProvider
of its parent Chain.
When called, it will
- Retrieve a value from the context using the given key
- Transform the value with the given function (optional)
- Return the value