Denoising diffusion models (DDMs) have shown promising results in 3D point cloud synthesis. To advance 3D DDMs and make them useful for digital artists, we require (i) high generation quality, (ii) flexibility for manipulation and applications such as conditional synthesis and shape interpolation, and (iii) the ability to output smooth surfaces or meshes. To this end, we introduce the hierarchical Latent Point Diffusion Model (LION) for 3D shape generation. LION is set up as a variational autoencoder (VAE) with a hierarchical latent space that combines a global shape latent representation with a point-structured latent space. For generation, we train two hierarchical DDMs in these latent spaces. The hierarchical VAE approach boosts performance compared to DDMs that operate on point clouds directly, while the point-structured latents are still ideally suited for DDM-based modeling. Experimentally, LION achieves state-of-the-art generation performance on multiple ShapeNet benchmarks. Furthermore, our VAE framework allows us to easily use LION for different relevant tasks without re-training the latent DDMs: We show that LION excels at multimodal shape denoising and voxel-conditioned synthesis. We also demonstrate shape autoencoding and latent shape interpolation, and we augment LION with modern surface reconstruction techniques to generate smooth 3D meshes. We hope that LION provides a powerful tool for artists working with 3D shapes due to its high-quality generation, flexibility, and surface reconstruction.
LION is set up as a hierarchical point cloud VAE with denoising diffusion models over the shape latent and latent point distributions. Point-Voxel CNNs (PVCNN) with adaptive Group Normalization (Ada. GN) are used as neural networks. The latent points can be interpreted as a smoothed version of the input point cloud. Shape As Points (SAP) is optionally used for mesh reconstruction.
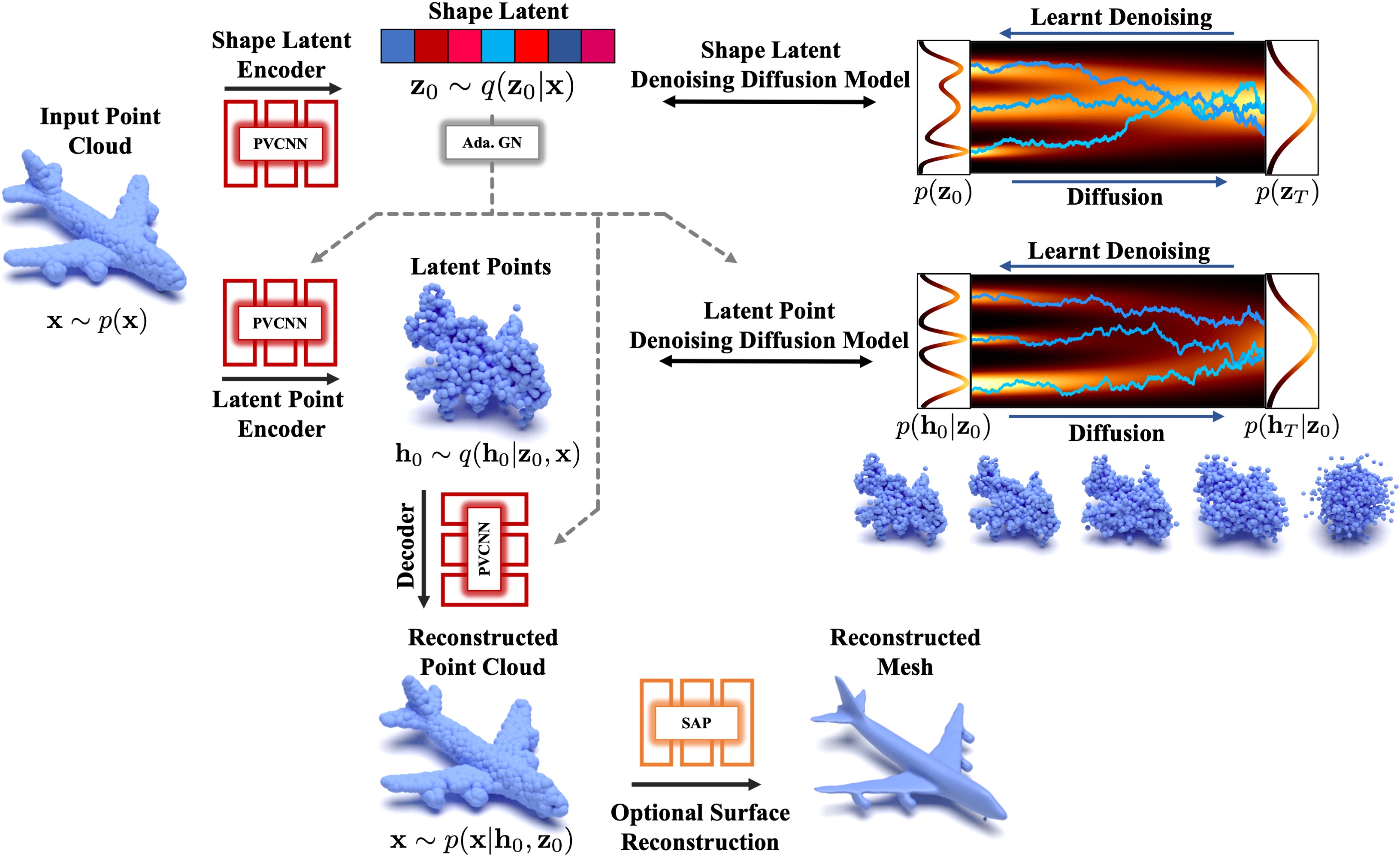
Architecture of LION.
We make the following technical contributions:
Samples from LION trained on single catgory.
Generated point clouds and reconstructed mesh of airplanes.
Generated point clouds and reconstructed mesh of chair.
Generated point clouds and reconstructed mesh of car.
Generated point clouds and reconstructed mesh of Animal.
Generated point clouds and reconstructed mesh of bottle.
Generated point clouds and reconstructed mesh of mug.
Generated point clouds and reconstructed mesh. LION model trained on 13 ShapeNet categories jointly without conditioning.
Generated point clouds and reconstructed mesh. LION model trained on 55 ShapeNet categories jointly without conditioning.
LION can interpolate two shapes by traversing the latent space. The generated shapes are clean and semantically plausible along the entire interpolation path.
Left most shape: the source shape. Right most shape: the target shape. The shapes in middle are interpolated results between source and target shape.
LION traverses the latent space and interpolates many different shapes.
The sampling time of LION can be reduced by applying DDIM sampler. DDIM sampler with 25 steps can already generate high-quality shapes, which takes less than 1 sec.
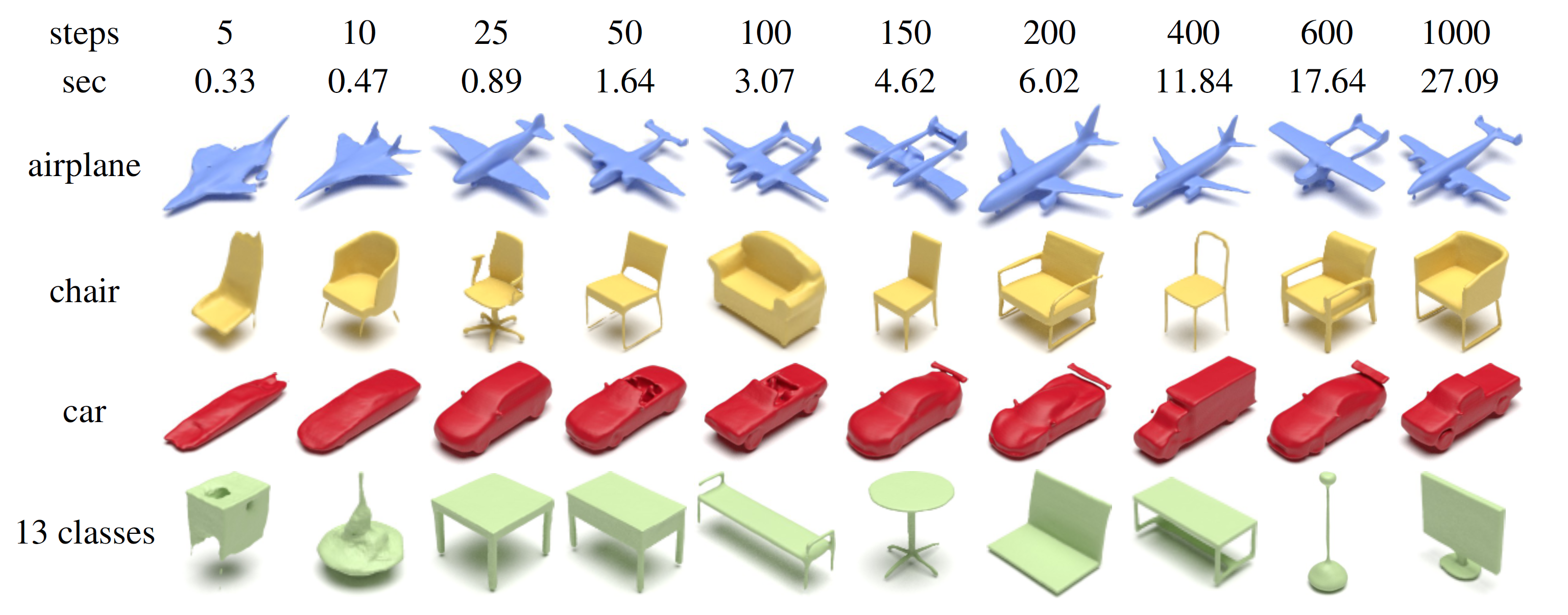
DDIM samples from LION trained on different data. The top two rows show the number of steps and the wall-clock time used when drawing one sample. With DDIM sampling, we can reduce the sampling time from 27.09 sec (1000 steps) to less than 1 sec (25 steps) to generate an object.
Given a coarse voxel grid, LION can generate different plausible detailed shapes.
In practice, an artist using a 3D generative model may have a rough idea of the desired shape. For instance, they may be able to quickly construct a coarse voxelized shape, to which the generative model then adds realistic details.
Left: Input voxel grid. Right: two point clouds generated by LION and the reconstructed mesh.
We extend LION to also allow for single view reconstruction (SVR) from RGB data. We render 2D images from the 3D ShapeNet shapes, extracted the images’ CLIP image embeddings, and trained LION’s latent diffusion models while conditioning on the shapes’ CLIP image embeddings. At test time, we then take a single view 2D image, extract the CLIP image embedding, and generate corresponding 3D shapes, thereby effectively performing SVR. We show SVR results from real RGB data


Single view reconstruction from RGB images of chair. For each input image, LION can generate multi-modal outputs.

More single view reconstruction from RGB images of car.
Using CLIP’s text encoder, our method additionally allows for text-guided generation.


Text-driven shape generation of chairs with LION. Bottom row is the text input
We apply Text2mesh on some generated meshes from LION to additionally synthesize textures in a text-driven manner, leveraging CLIP. The original mesh is generated by LION.







LION: Latent Point Diffusion Models for 3D Shape Generation
Xiaohui Zeng, Arash Vahdat, Francis Williams, Zan Gojcic, Or Litany, Sanja Fidler, Karsten Kreis
Advances in Neural Information Processing Systems (NeurIPS), 2022
@inproceedings{
zeng2022lion,
title={ LION: Latent Point Diffusion Models for 3D Shape Generation },
author={ Xiaohui Zeng and Arash Vahdat and Francis Williams and Zan Gojcic and Or Litany and Sanja Fidler and Karsten Kreis },
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}