## LION: Latent Point Diffusion Models for 3D Shape Generation
NeurIPS 2022
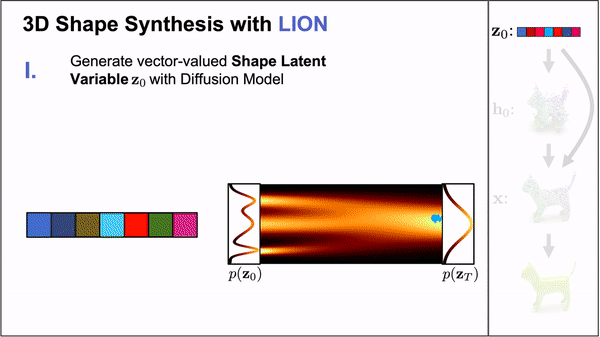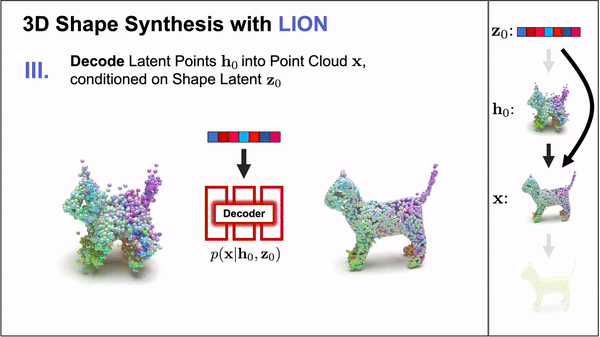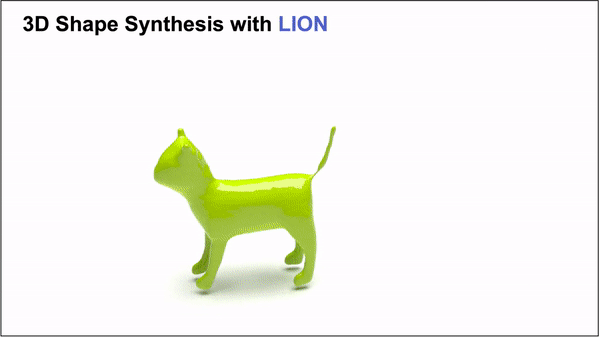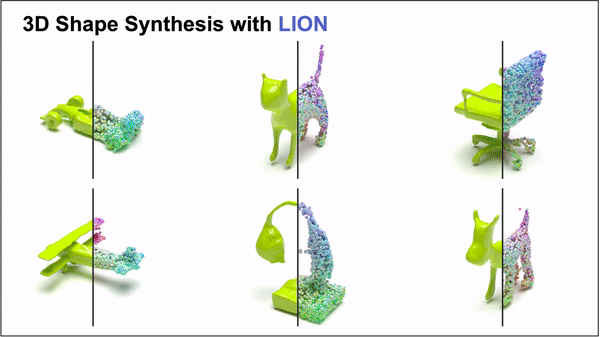
## Update
* add pointclouds rendering code used for paper figure, see `utils/render_mitsuba_pc.py`
* When opening an issue, please add @ZENGXH so that I can reponse faster!
## Install
* Dependencies:
* CUDA 11.6
* Setup the environment
Install from conda file
```
conda env create --name lion_env --file=env.yaml
conda activate lion_env
# Install some other packages
pip install git+https://github.com/openai/CLIP.git
# build some packages first (optional)
python build_pkg.py
```
Tested with conda version 22.9.0
* Using Docker
* build the docker with `bash ./docker/build_docker.sh`
* launch the docker with `bash ./docker/run.sh`
## Demo
run `python demo.py`, will load the released text2shape model on hugging face and generate a chair point cloud. (Note: the checkpoint is not released yet, the files loaded in the `demo.py` file is not available at this point)
## Released checkpoint and samples
* will be release soon
* after download, run the checksum with `python ./script/check_sum.py ./lion_ckpt.zip`
* put the downloaded file under `./lion_ckpt/`
## Training
### data
* ShapeNet can be downloaded [here](https://github.com/stevenygd/PointFlow#dataset).
* Put the downloaded data as `./data/ShapeNetCore.v2.PC15k` *or* edit the `pointflow` entry in `./datasets/data_path.py` for the ShapeNet dataset path.
### train VAE
* run `bash ./script/train_vae.sh $NGPU` (the released checkpoint is trained with `NGPU=4` on A100)
* if want to use comet to log the experiment, add `.comet_api` file under the current folder, write the api key as `{"api_key": "${COMET_API_KEY}"}` in the `.comet_api` file
### train diffusion prior
* require the vae checkpoint
* run `bash ./script/train_prior.sh $NGPU` (the released checkpoint is trained with `NGPU=8` with 2 node on V100)
### train diffusion prior with clip feat
* this script trains model for single-view-reconstruction or text2shape task
* the idea is that we take the encoder and decoder trained on the data as usual (without conditioning input), and when training the diffusion prior, we feed the clip image embedding as conditioning input: the shape-latent prior model will take the clip embedding through AdaGN layer.
* require the vae checkpoint trained above
* require the rendered ShapeNet data, you can render yourself or download it from [here](https://github.com/autonomousvision/occupancy_networks#preprocessed-data)
* put the rendered data as `./data/shapenet_render/` or edit the `clip_forge_image` entry in `./datasets/data_path.py`
* the img data will be read under `./datasets/pointflow_datasets.py` with the `render_img_path`, you may need to cutomize this variable depending of the folder structure
* run `bash ./script/train_prior_clip.sh $NGPU`
### (Optional) monitor exp
* (tested) use comet-ml: need to add a file `.comet_api` under this `LION` folder, example of the `.comet_api` file:
```
{"api_key": "...", "project_name": "lion", "workspace": "..."}
```
* (not tested) use wandb: need to add a `.wandb_api` file, and set the env variable `export USE_WB=1` before training
```
{"project": "...", "entity": "..."}
```
* (not tested) use tensorboard, set the env variable `export USE_TFB=1` before training
* see the `utils/utils.py` files for the details of the experiment logger; I usually use comet-ml for my experiments
### evaluate a trained prior
* download the test data (Table 1) from [here](https://drive.google.com/file/d/1uEp0o6UpRqfYwvRXQGZ5ZgT1IYBQvUSV/view?usp=share_link), unzip and put it as `./datasets/test_data/`
* download the released checkpoint from above
```
checkpoint="./lion_ckpt/unconditional/airplane/checkpoints/model.pt"
bash ./script/eval.sh $checkpoint # will take 1-2 hour
```
#### other test data
* ShapeNet-Vol test data:
* please check [here](https://github.com/nv-tlabs/LION/issues/20#issuecomment-1436315100) before using this data
* [all category](https://drive.google.com/file/d/1QXrCbYKjTIAnH1OhZMathwdtQEXG5TjO/view?usp=sharing): 1000 shapes are sampled from the full validation set
* [chair, airplane, car](https://drive.google.com/file/d/11ZU_Bq5JwN3ggI7Ffj4NAjIxxhc2pNZ8/view?usp=share_link)
* table 21 and table 20, point-flow test data
* check [here](https://github.com/nv-tlabs/LION/issues/26#issuecomment-1466915318) before using this data
* [mug](https://drive.google.com/file/d/1lvJh2V94Nd7nZPcRqsCwW5oygsHOD3EE/view?usp=share_link) and [bottle](https://drive.google.com/file/d/1MRl4EgW6-4hOrdRq_e2iGh348a0aCH5f/view?usp=share_link)
* 55 catergory [data](https://drive.google.com/file/d/1Rbj1_33sN_S2YUbcJu6h922tKuJyQ2Dm/view?usp=share_link)
## Evaluate the samples with the 1-NNA metrics
* download the test data from [here](https://drive.google.com/file/d/1uEp0o6UpRqfYwvRXQGZ5ZgT1IYBQvUSV/view?usp=share_link), unzip and put it as `./datasets/test_data/`
* run `python ./script/compute_score.py` (Note: for ShapeNet-Vol data and table 21, 20, need to set `norm_box=True`)
## Citation
```
@inproceedings{zeng2022lion,
title={LION: Latent Point Diffusion Models for 3D Shape Generation},
author={Xiaohui Zeng and Arash Vahdat and Francis Williams and Zan Gojcic and Or Litany and Sanja Fidler and Karsten Kreis},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}
```