337 lines
8.7 KiB
Markdown
337 lines
8.7 KiB
Markdown
---
|
||
marp: true
|
||
paginate: true
|
||
author: Laurent Fainsin, Damien Guillotin, Pierre-Eliot Jourdan
|
||
math: katex
|
||
---
|
||
|
||
<style>
|
||
section::after {
|
||
/*custom pagination*/
|
||
content: attr(data-marpit-pagination) ' / ' attr(data-marpit-pagination-total);
|
||
}
|
||
</style>
|
||
|
||
<style scoped>
|
||
h1, h2 {
|
||
color: white;
|
||
}
|
||
</style>
|
||
|
||
# Projet IAM
|
||
## SimCLR + SGAN
|
||
|
||

|
||
|
||
<footer>
|
||
|
||
Laurent Fainsin, Damien Guillotin, Pierre-Eliot Jourdan
|
||
|
||
</footer>
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Sujet
|
||
|
||
</header>
|
||
|
||
<style scoped>
|
||
table, td, th, tr {
|
||
border: none !important;
|
||
border-collapse: collapse !important;
|
||
border-style: none !important;
|
||
background-color: unset !important;
|
||
overflow: hidden;
|
||
margin: auto;
|
||
text-align: center;
|
||
}
|
||
</style>
|
||
|
||
Images d'animaux $\rightarrow$ 18 classes différentes
|
||
|
||
| | | |
|
||
| :----------------------------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------: |
|
||
|  |  |  |
|
||
|  |  |  |
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Sujet
|
||
|
||
</header>
|
||
|
||
### Dataset
|
||
- Données labellisées $\rightarrow$ 20 images/classe $\rightarrow$ 360 images
|
||
- Données non labellisées $\rightarrow$ 2000 images
|
||
- Données de test $\rightarrow$ 100 images/classe $\rightarrow$ 1800 images
|
||
|
||
### Model
|
||
- Input $\rightarrow$ 128x128px
|
||
- Network $\rightarrow$ [MobileNetV1](https://www.tensorflow.org/api_docs/python/tf/compat/v1/keras/applications/mobilenet)
|
||
|
||
<!-- Les consignes à respecter -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Méthode contrastive <br> (SimCLR)
|
||
|
||
</header>
|
||
|
||

|
||
|
||
<!--
|
||
|
||
augmentations: cf slide suivante
|
||
CNN (le même dans les deux colonnes): mobilenetv1
|
||
representation: espace latent de taille `width` = 128
|
||
MLP: multi layer perceptron (projection head) -> taille sortie = `width` = 128
|
||
linear probe (non représenté) -> input: representation latente -> couche dense -> taille sortie = len(labels) = 18
|
||
|
||
pendant le training: on encode nos images dans l'espace latent (`representation`). Ensuite y'a deux trucs:
|
||
1. on projete notre espace latent via un MLP et on calcule la contrastive loss (qui va se charger de attract/repel).
|
||
2. on calcul un label via le linear probe sur l'espace latent (`representation`), et on calcul une loss via SparseCategoricalCrossentropy.
|
||
|
||
Une fois qu'on a nos deux loss (et nos gradients lors du forward) on rétropropage tout (on update nos paramètres quoi), et on passe au batch suivant.
|
||
|
||
À noter que lors de l'inférence on se sert pas du MLP, donc on peut le jeter.
|
||
|
||
-->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
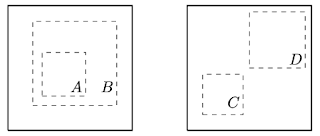
# Augmentations
|
||
|
||
</header>
|
||
|
||
<div style="display: flex; align-items: center;">
|
||
|
||

|
||
|
||
|
||
|
||
</div>
|
||
|
||
<!-- Pleins d'augmentations possible, mais google trouve que les seules nécéssaires pour avoir au moins des bonnes perfs sont le cropping (spécial, cf figure droite) et le jittering -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Méthode contrastive <br> (SimCLR)
|
||
|
||
</header>
|
||
|
||

|
||
|
||
<!--
|
||
|
||
intuition derrière:
|
||
|
||
en supervisé c'est super simple de trouver les frontière pour la classif, juste on calcule la loss, et avec le gradient ça fait bouger. Ici on a pas ce luxe, du coup on par du principe qu'une image, même augmenté est à peut près au même endroit dans la répartition de l'espace, d'où le fait qu'on va essayer de faire en sorte que ça soit le cas via le contrastive loss (next slide). Nous en plus on va venir parsement d'images supervisée pour "régulariser" un peu le tout
|
||
|
||
-->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Contrastive loss
|
||
|
||
</header>
|
||
|
||
$$l_{i,j} = -\log \frac{ \exp( \text{sim}(z_i, z_j) / \tau ) }{\sum^{2N}_{k=1\neq i} \exp( \text{sim}(z_i, z_j) / \tau) }$$
|
||
|
||
<!--
|
||
|
||
sim -> cosine distance
|
||
+ en gros un softmax
|
||
+ le tout dans un log
|
||
|
||
tau -> température (hyper paramètre)
|
||
|
||
-->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Résultats fully-supervised
|
||
|
||
</header>
|
||
|
||

|
||

|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Résultats semi-supervised
|
||
|
||
</header>
|
||
|
||

|
||

|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Résultats supervised fine-tuning
|
||
|
||
</header>
|
||
|
||

|
||

|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Comparaison des résultats
|
||
|
||
</header>
|
||
|
||
<style scoped>
|
||
img {
|
||
margin: auto;
|
||
margin-top: 2.5rem;
|
||
display: block;
|
||
}
|
||
</style>
|
||
|
||

|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Méthode générative (SGAN)
|
||
|
||
</header>
|
||
|
||

|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Architecture du SGAN
|
||
|
||
</header>
|
||
|
||

|
||
|
||
<!-- Générateur : 3,425,155 paramètres -->
|
||
|
||

|
||
|
||
<!-- Discriminateur : 710,930 paramètres (708,737) -->
|
||
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Résultats générateur
|
||
|
||
</header>
|
||
|
||
<style scoped>
|
||
table, td, th, tr {
|
||
border: none !important;
|
||
border-collapse: collapse !important;
|
||
border-style: none !important;
|
||
background-color: unset !important;
|
||
overflow: hidden;
|
||
margin: auto;
|
||
text-align: center;
|
||
}
|
||
</style>
|
||
|
||
| | 5 epochs | 100 epochs |
|
||
| :---------------------------------------: | :----------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------: |
|
||
| <p style="font-size:1.5rem">!pretrain</p> |  |  |
|
||
| <p style="font-size:1.5rem">pretrain</p> |  |  |
|
||
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Résultats fully-supervised
|
||
|
||
</header>
|
||
|
||
<style scoped>
|
||
img {
|
||
margin: auto;
|
||
margin-top: 2.5rem;
|
||
display: block;
|
||
}
|
||
</style>
|
||
|
||

|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Résultats semi-supervised
|
||
|
||
</header>
|
||
|
||
<style scoped>
|
||
img {
|
||
margin: auto;
|
||
margin-top: 2.5rem;
|
||
display: block;
|
||
}
|
||
</style>
|
||
|
||

|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Résultats pre-training
|
||
|
||
</header>
|
||
|
||
<style scoped>
|
||
img {
|
||
margin: auto;
|
||
margin-top: 2.5rem;
|
||
display: block;
|
||
}
|
||
</style>
|
||
|
||

|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Comparaison des résultats
|
||
|
||
</header>
|
||
|
||
<style scoped>
|
||
img {
|
||
margin: auto;
|
||
margin-top: 2.5rem;
|
||
display: block;
|
||
}
|
||
</style>
|
||
|
||

|