13 KiB
13 KiB
| marp | paginate | author | math |
|---|---|---|---|
| true | true | Clément Contet, Laurent Fainsin | katex |
The RAFT Consensus Algorithm
![]()
Diego Ongaro, John Ousterhout, Stanford University (2014)
Consensus
Consensus algorithms allow a collection of machines to work as a coherent group that can survive the failures of some of its members. – RAFT authors
- Accord sur l'état du système (image système unique et partagée)
- Réparation (réplication) autonome en cas de défaillance d'un serveur
- Une minorité de serveurs HS: pas de problème
- La majorité des serveurs HS: perte de disponibilité, maintien de la cohérence
- La clé pour construire des systèmes de stockage cohérents
Organisation typique des state machine replication

Paxos (Paxos Made Simple. Leslie Lamport, ACM SIGACT News, 2001.)
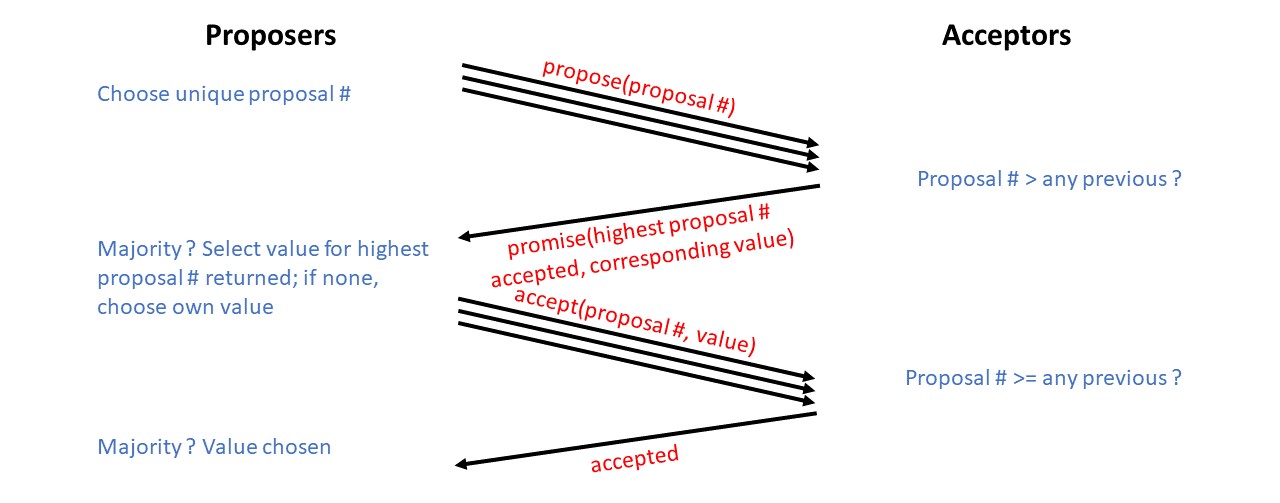
Le problème avec Paxos
Paxos domine le marché depuis ~25 ans (Leslie Lamport, 1989)
- Difficile à comprendre
- Difficile à implémenter
The dirty little secret of the NSDI community is that at most five people really, truly understand every part of Paxos ;-). – NSDI reviewer
There are significant gaps between the description of the Paxos algorithm and the needs of a real-world system…the final system will be based on an unproven protocol. – Chubby authors
Une autre proposition : RAFT
Prendre des décisions de conception fondées sur la compréhensibilité
- Décomposition du problème
- Minimiser l'espace des états
- Traiter plusieurs problèmes avec un seul mécanisme
- Éliminer les cas particuliers
- Minimiser le non-déterminisme
- Maximiser la cohérence
Décomposition du problème
- Élection d'un leader (mandat)
- Sélectionner un serveur qui sera le leader
- Détecter les pannes, choisir un nouveau leader
- Réplication des logs (fonctionnement normal)
- Le leader accepte les commandes des clients et les ajoute à son journal
- Le leader réplique son journal aux autres serveurs (écrase les incohérences)
- Sécurité
- Maintenir la cohérence des journaux
- Seuls les serveurs dont les journaux sont à jour peuvent devenir des leaders
Minimiser l'espace des états
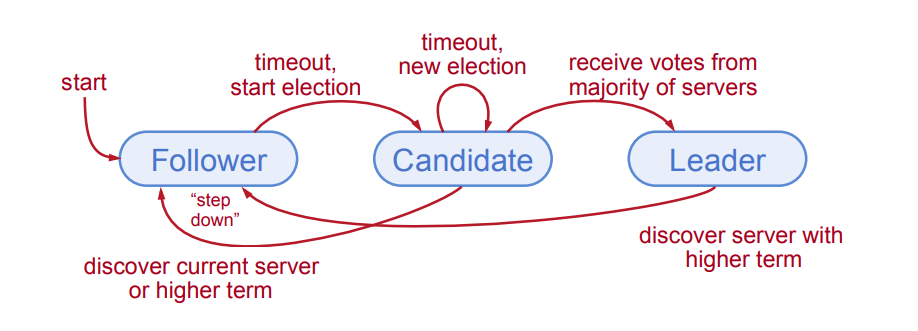
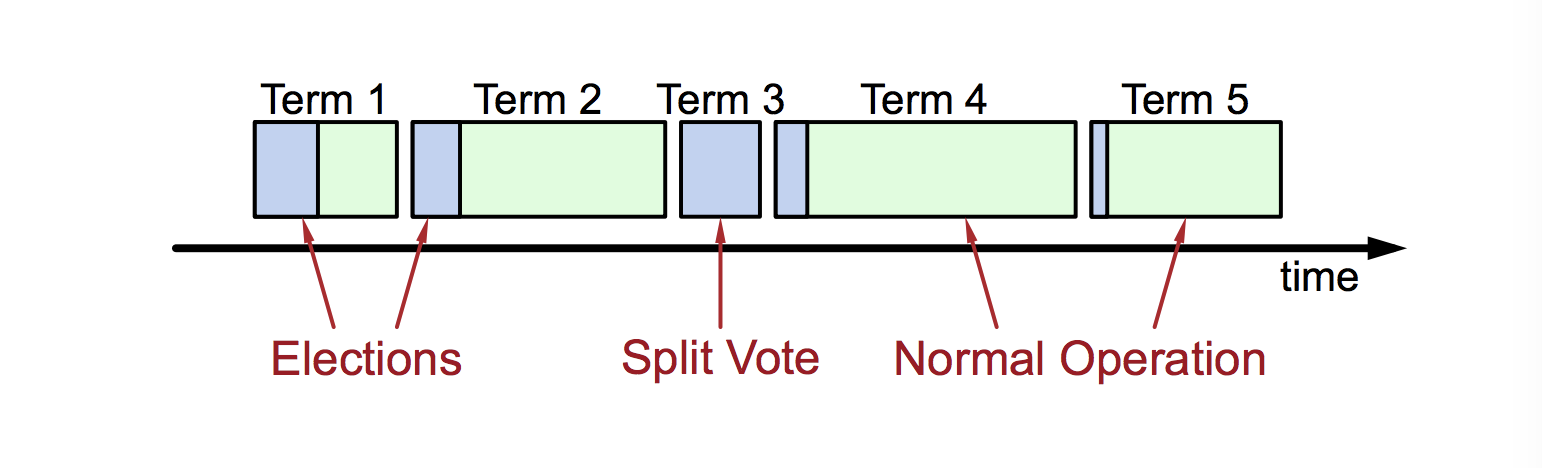
Mandats
Élection du leader
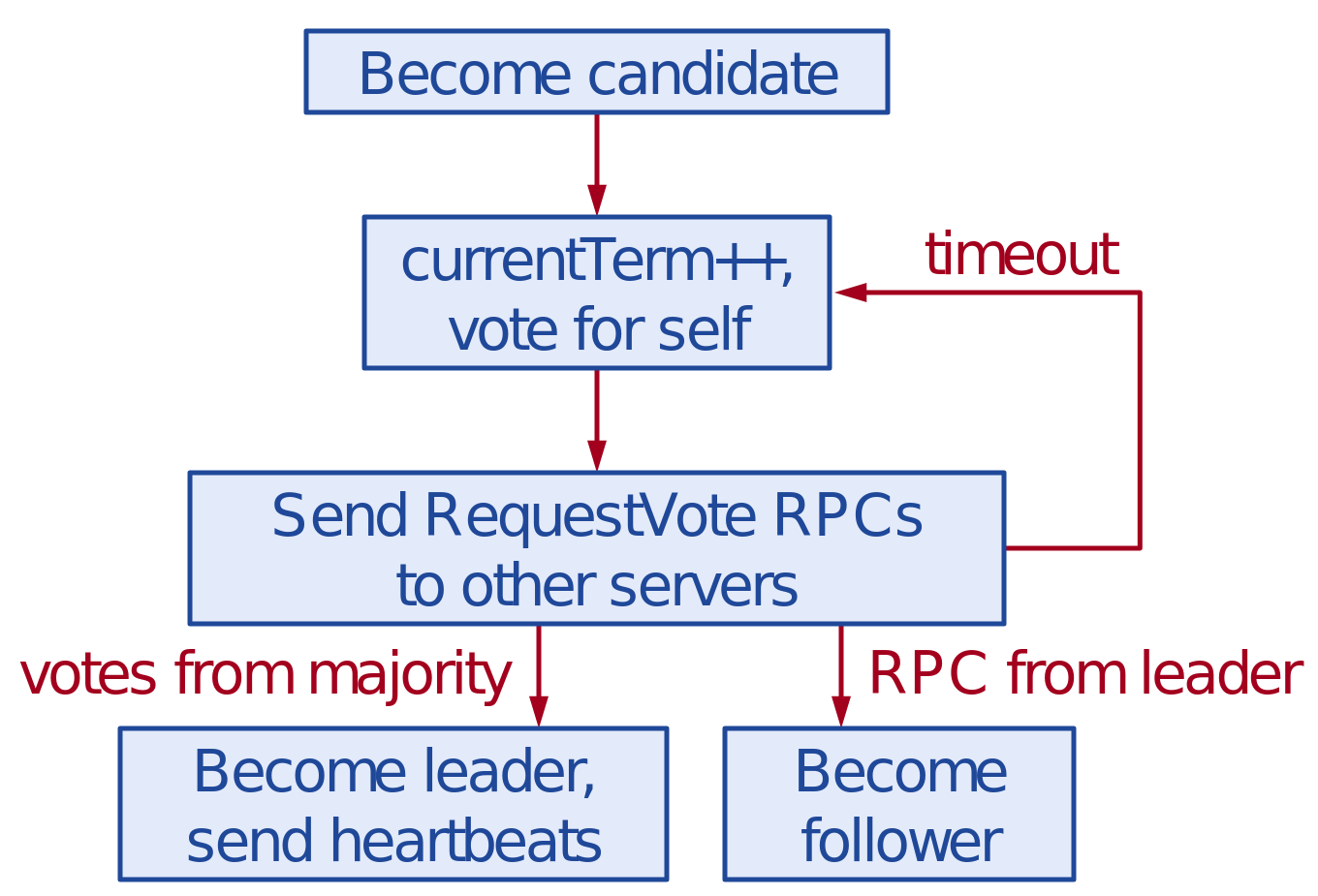
Correction des élections
- Sécurité: autoriser au maximum un gagnant par mandat
- Chaque serveur ne donne qu'un seul vote par mandat (persistant sur disque)
- Majorité requise pour gagner l'élection

- Vivacité: un candidat doit finir par gagner
- Délais d'expiration des élections aléatoire dans
[T, 2T](e.g. 150-300 ms) - Le serveur gagne l'élection en dépassant le délai d'attente avant les autres
- Fonctionne bien si
T_{\text{diffusion}} \ll T \ll \text{MTBF}
- Délais d'expiration des élections aléatoire dans
- Approche aléatoire plus simple que les autres comme le ranking
Démo interactive
Structure des journaux
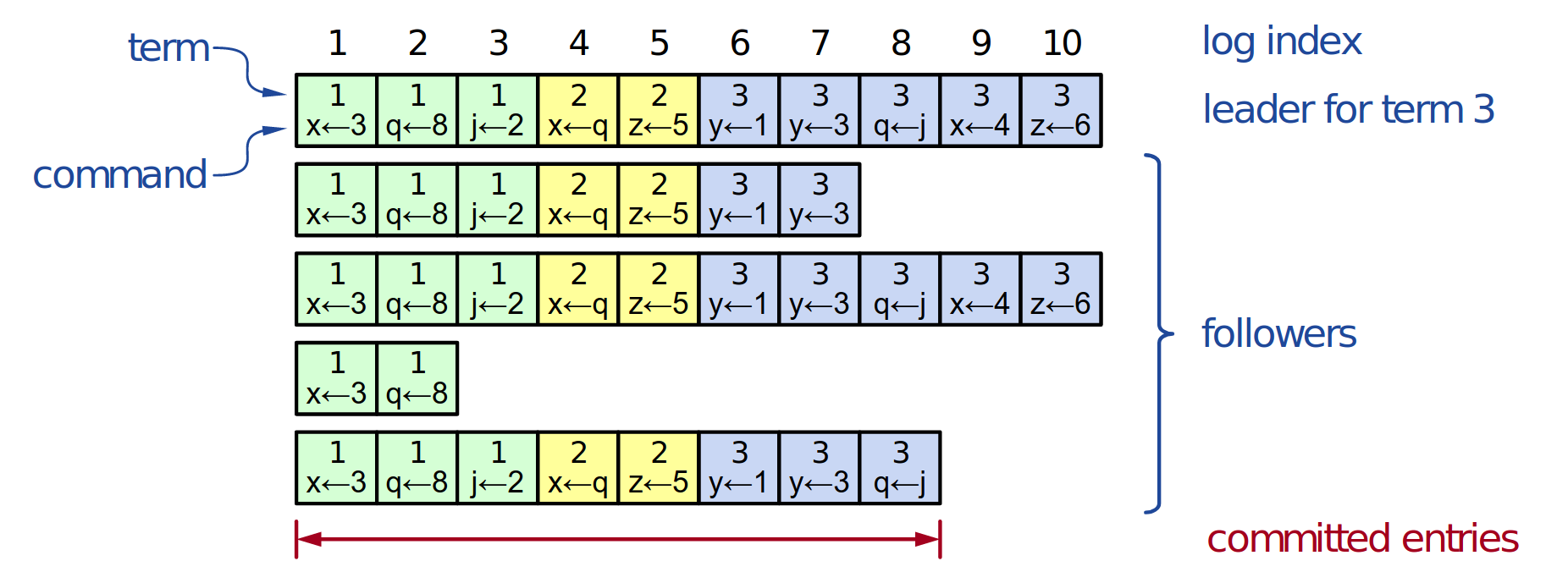
Incohérences des journaux
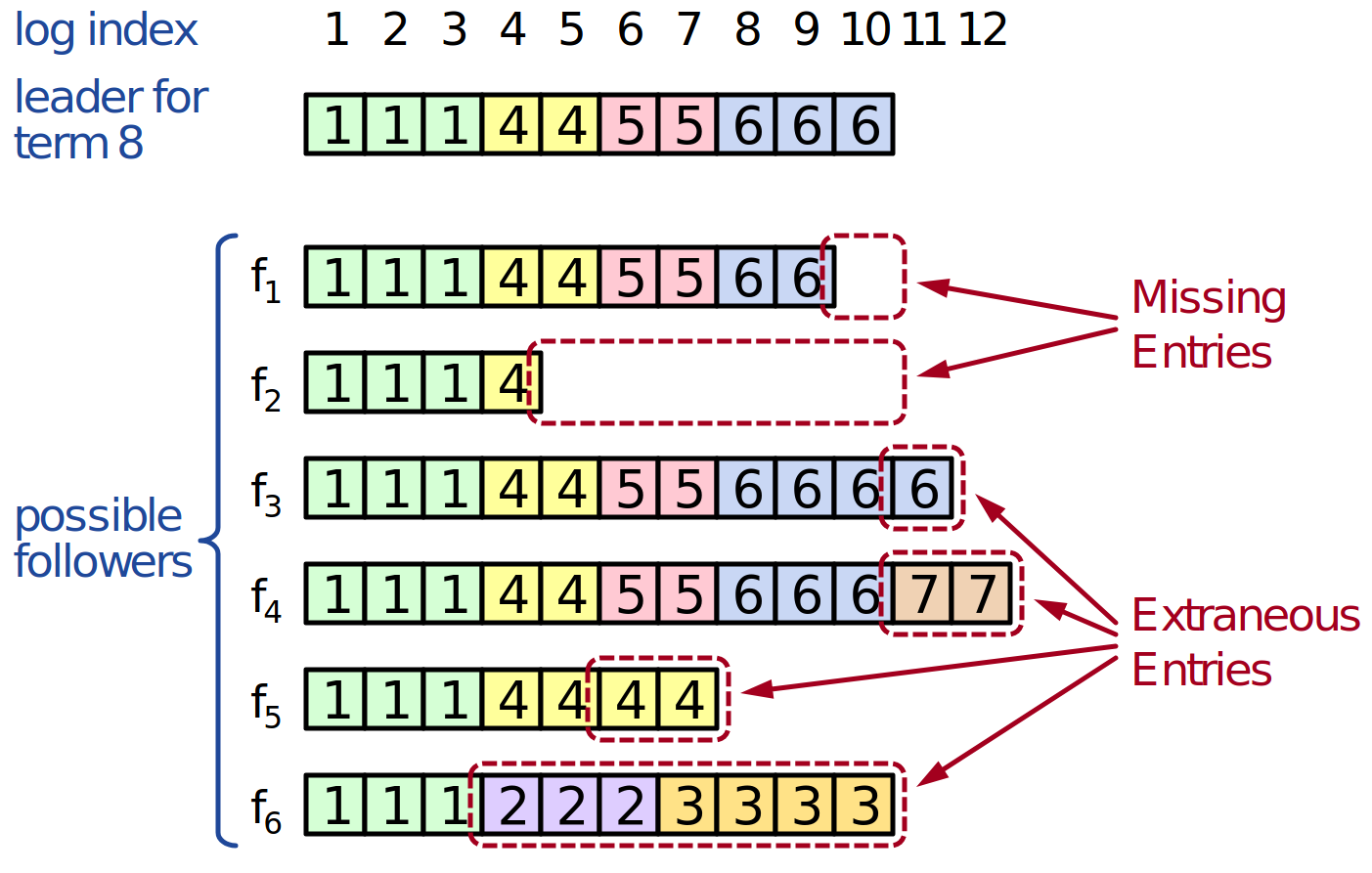
Propriété de correspondance des journaux
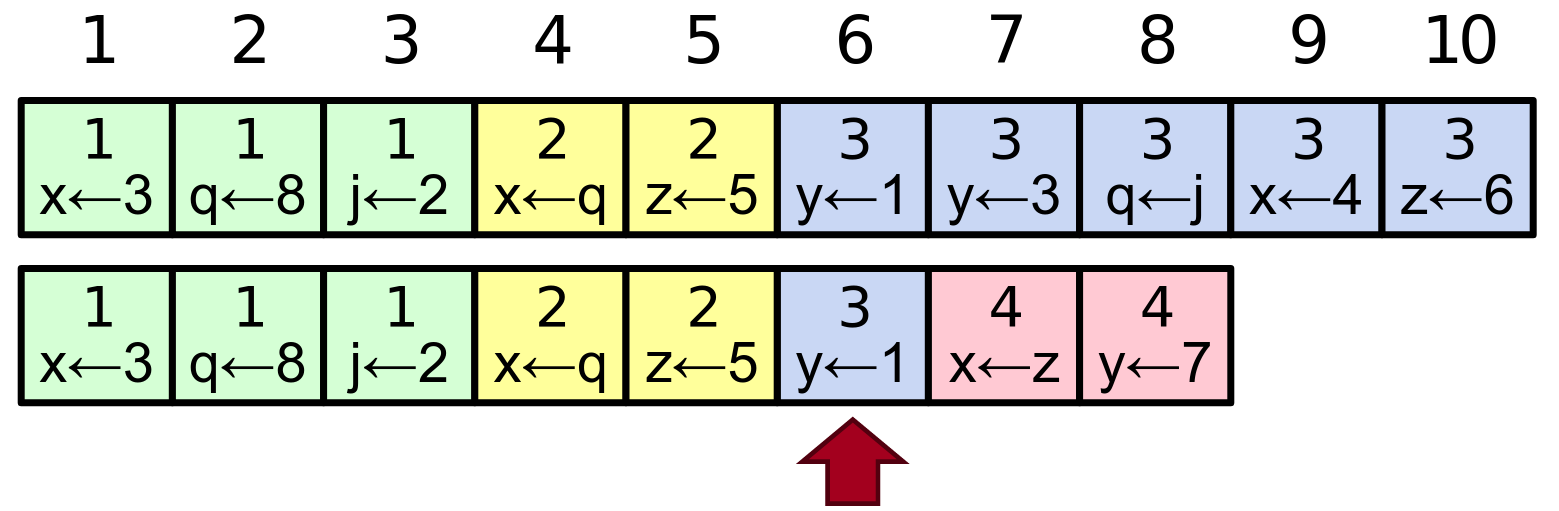
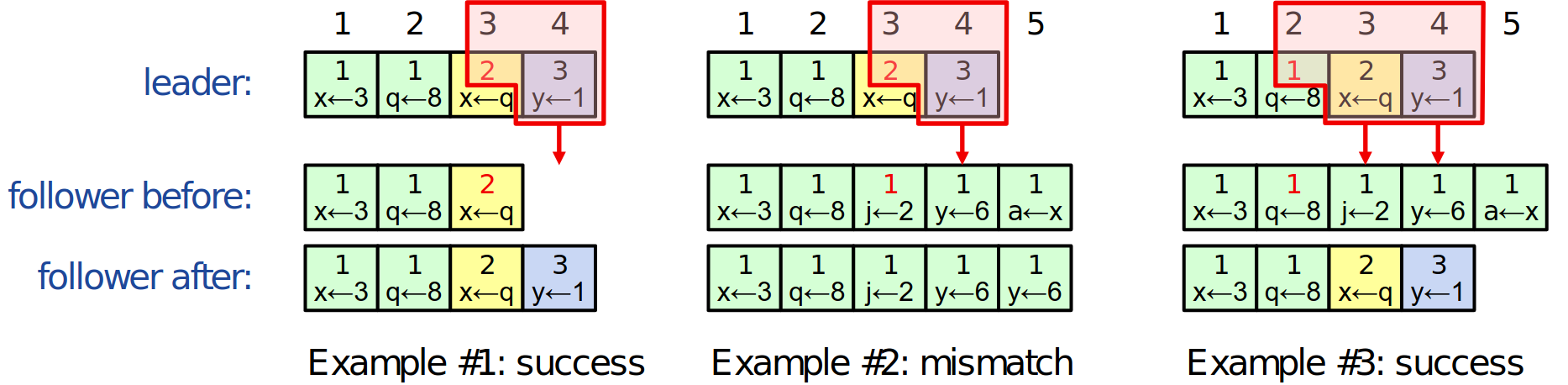
Réparation des journaux par correspondance
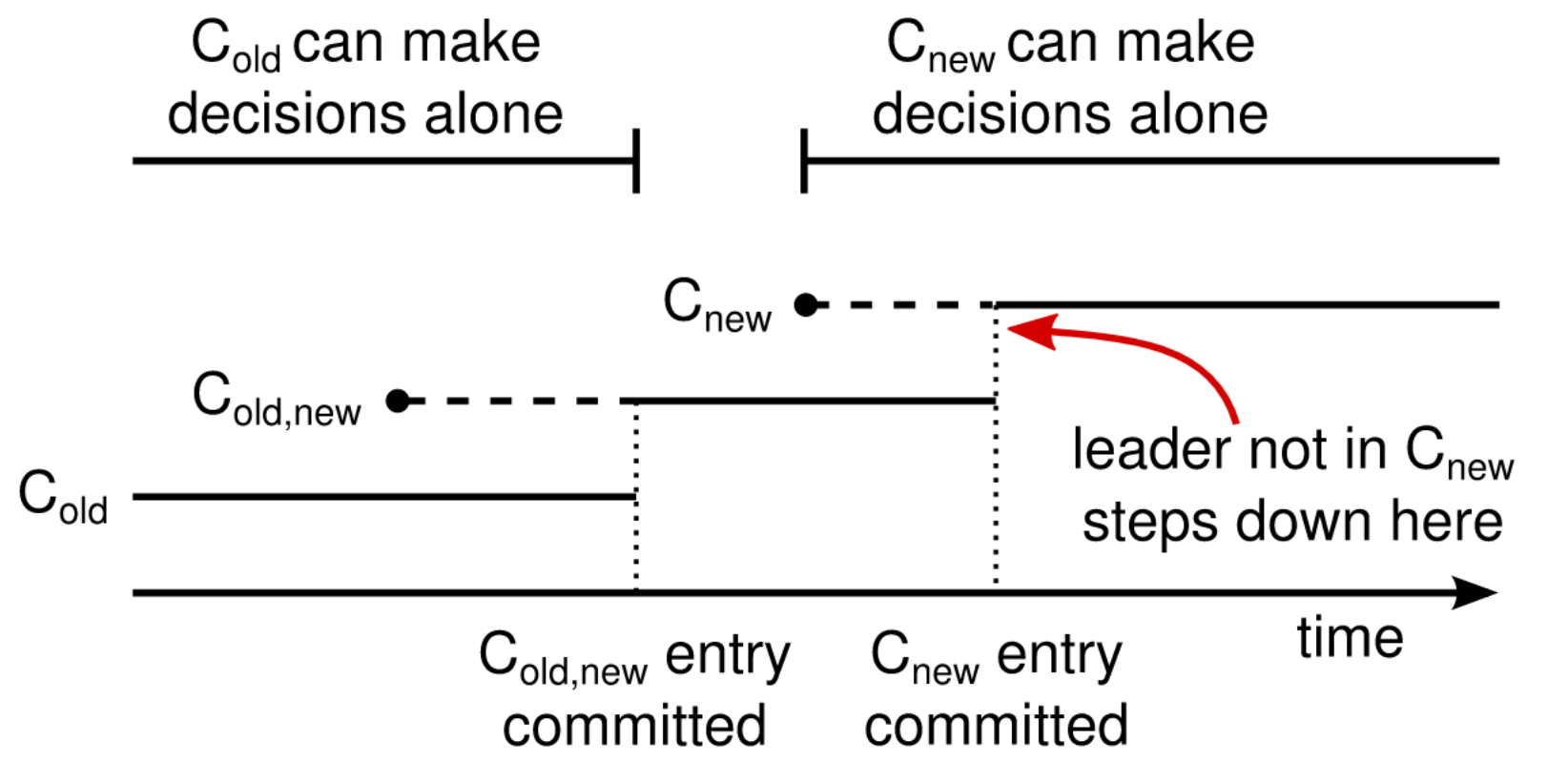
Changement de composition du cluster
De nombreuses implémentations
| Name | Primary Authors | Language | License |
|---|---|---|---|
| etcd/raft | Blake Mizerany, Xiang Li and Yicheng Qin (CoreOS) | Go | Apache 2.0 |
| go-raft | Ben Johnson (Sky) and Xiang Li (CMU, CoreOS) | Go | MIT |
| hashicorp/raft | Armon Dadgar (hashicorp) | Go | MPL-2.0 |
| copycat | Jordan Halterman | Java | Apache2 |
| LogCabin | Diego Ongaro (Stanford, Scale Computing) | C++ | ISC |
| akka-raft | Konrad Malawski | Scala | Apache2 |
| kanaka/raft.js | Joel Martin | Javascript | MPL-2.0 |
Quel degré de hasard est nécessaire pour éviter les votes non concluants ?

Étude: Raft est-il plus simple que Paxos ?

