498 lines
13 KiB
Markdown
498 lines
13 KiB
Markdown
---
|
||
marp: true
|
||
paginate: true
|
||
author: Clément Contet, Laurent Fainsin
|
||
math: katex
|
||
---
|
||
|
||
<style>
|
||
section::after {
|
||
/*custom pagination*/
|
||
content: attr(data-marpit-pagination) ' / ' attr(data-marpit-pagination-total);
|
||
}
|
||
</style>
|
||
|
||
# The RAFT Consensus Algorithm
|
||
|
||
<!-- https://github.com/raft/raft.github.io -->
|
||
<!-- https://ongardie.net/static/coreosfest/slides -->
|
||
|
||

|
||
|
||
<footer>
|
||
Reliable, Replicated, Redundant, And Fault-Tolerant.<br>
|
||
Diego Ongaro,
|
||
John Ousterhout,
|
||
Stanford University
|
||
(2014)
|
||
</footer>
|
||
|
||
<!-- mascotte: annie -->
|
||
|
||
<!-- Laurent -->
|
||
|
||
---
|
||
|
||
<!-- Qu'est ce que le "consensus" dans un premier temps ? -->
|
||
|
||
<header>
|
||
|
||
# Consensus
|
||
|
||
</header>
|
||
|
||
> Consensus algorithms allow a collection of machines to work as a coherent group that can survive the failures of some of its members. – RAFT authors
|
||
|
||
<!-- Pour citer les auteurs de raft (dans leur abstract) -->
|
||
|
||
<!-- Les algorithmes de consensus permettent à un ensemble de machines de fonctionner comme un groupe cohérent qui peut survivre aux défaillances de certains de ses membres. -->
|
||
|
||
<br>
|
||
|
||
<!-- Donc globalement ça veut dire qu'un algorithme de consensus doit permettre / permet -->
|
||
|
||
<!-- accord implique réparation -->
|
||
<!-- en découle que c'est un point clé pour build sys cohérent -->
|
||
|
||
- Accord sur l'état du système (image système unique et partagée)
|
||
- Réparation (réplication) autonome en cas de défaillance d'un serveur
|
||
- Une minorité de serveurs HS: pas de problème
|
||
- La majorité des serveurs HS: perte de disponibilité, maintien de la cohérence
|
||
- La clé pour construire des systèmes de stockage cohérents
|
||
|
||
<!-- Laurent -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Organisation typique des state machine replication
|
||
|
||
</header>
|
||
|
||

|
||
|
||
<!-- Un ou plusieurs clients. Et plusieurs serveurs formant un groupe de consensus (généralement > 3 et impair). Quand client RPC serv, leader réplique cela sur ses suiveurs et une fois cela validé, répond au client. -->
|
||
|
||
<!--
|
||
|
||
- Replicated state machine <- Replicated log (inférence)
|
||
- All servers execute same commands in same order
|
||
- Consensus module ensures proper log replication
|
||
- System makes progress as long as any majority of servers up
|
||
- Failure model: fail-stop (not Byzantine), delayed/lost msgs
|
||
|
||
-->
|
||
|
||
<!-- Laurent -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Paxos (Paxos Made Simple. Leslie Lamport, ACM SIGACT News, 2001.)
|
||
|
||
</header>
|
||
|
||

|
||
|
||
<!-- Clément -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Le problème avec Paxos
|
||
|
||
</header>
|
||
|
||
<!-- Avant RAFT il existait déjà un algorithme bien connu du nom de Paxos qui dominait sur le reste des algos de consensus. -->
|
||
|
||
<!-- Alors pourquoi faire un nouvel algo ? quels sont les motivations des auteurs ? -->
|
||
|
||
Paxos domine le marché depuis ~25 ans (Leslie Lamport, 1989)
|
||
- Difficile à comprendre
|
||
- Difficile à implémenter
|
||
|
||
> The dirty little secret of the NSDI community is that at most five people really, truly understand every part of Paxos ;-). – [NSDI](https://www.usenix.org/conference/nsdi23) reviewer
|
||
|
||
> There are significant gaps between the description of the Paxos algorithm and the needs of a real-world system…the final system will be based on an unproven protocol. – [Chubby](https://research.google/pubs/pub27897/) authors
|
||
|
||
<!-- Clément -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Une autre proposition : RAFT
|
||
|
||
</header>
|
||
|
||
<!-- Les auteurs de RAFT en avait donc ras le bol de voir cette situation, ils ont donc décidés de créer un nouvel algorithme, en se fondant sur la compréhensibilité -->
|
||
|
||
## Prendre des décisions de conception fondées sur la compréhensibilité
|
||
|
||
<!-- Pour se faire ils ont choisis de décomposer le consensus le plus possible en des petits problèmes trivials à résoudre. -->
|
||
|
||
- Décomposition du problème
|
||
|
||
<!-- Il ont aussi essayé de diminuer l'espace des états possibles lors du fonctionnement de l'algorithme pour le rendre le plus simple possible. -->
|
||
|
||
<!-- Une pière deux coup, c'est moins de code, moins de trucs à comprendre -->
|
||
<!-- rejoint l'idée traiter plusieurs mécanismes en même temps -->
|
||
<!-- rendre les états "prédictibles" (assez ironique sachant qu'ils utilisent de l'aléatoire) -->
|
||
|
||
- Minimiser l'espace des états
|
||
- Traiter plusieurs problèmes avec un seul mécanisme
|
||
- Éliminer les cas particuliers
|
||
- Minimiser le non-déterminisme
|
||
- Maximiser la cohérence
|
||
|
||
<!-- Laurent -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Décomposition du problème
|
||
|
||
</header>
|
||
|
||
<!-- Élection: Ils ont décidé de partir sur un modèle "strong leader" où le leader est source de vérité. Même si ça implique l'overhead de l'élection... ils ont trouvé que c'était plus facile à comprendre. -->
|
||
|
||
<!-- Réplication des logs: modèle hiérarchique, le serveur dicte à chaque candidats les modifications à apppliquer à ses journeaux. (append uniquement, sauf cas spéciaux qu'on verra après) -->
|
||
|
||
<!-- Sécurité: par de réparation active du leader des journeaux (par exemple juste après un crash), raft essaie de maintenir le plus possible la cohérence des journeaux et ainsi contourne le problème. -->
|
||
|
||
1. Élection d'un leader (mandat)
|
||
- Sélectionner un serveur qui sera le leader
|
||
- Détecter les pannes, choisir un nouveau leader
|
||
2. Réplication des logs (fonctionnement normal)
|
||
- Le leader accepte les commandes des clients et les ajoute à son journal
|
||
- Le leader réplique son journal aux autres serveurs (écrase les incohérences)
|
||
3. Sûreté
|
||
- Maintenir la cohérence des journaux
|
||
- Seuls les serveurs dont les journaux sont à jour peuvent devenir des leaders
|
||
|
||
<!-- Laurent -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
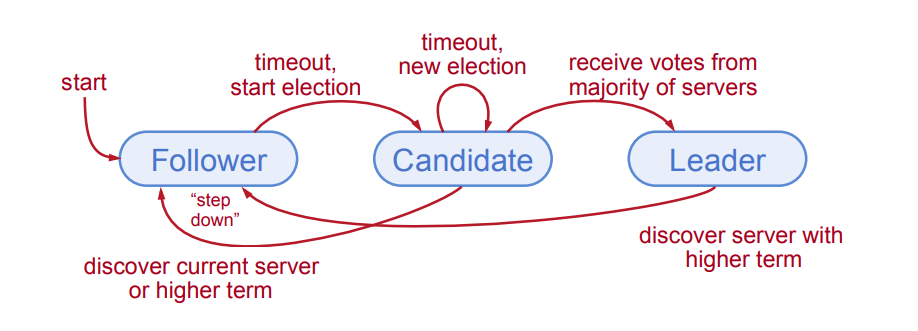
# Minimiser l'espace des états
|
||
|
||
</header>
|
||
|
||
<!--
|
||
Il n'y a que 3 états possibles pour les serveurs !
|
||
Et les changements d'états sont assez simples. -->
|
||
|
||
|
||
|
||
<!--
|
||
|
||
Follower: Passive (but expects regular heartbeats to stay in this state, get a random timeout time at startup), if after some time there is no heartbeat, timeout, change to candidate.
|
||
|
||
(RPC: https://en.wikipedia.org/wiki/Remote_procedure_call)
|
||
|
||
Candidate: Issues RequestVote RPCs to get elected as leader. After results, if majority, becomes new leader. if other leader gets elected or is already present, step down.
|
||
|
||
|
||
Leader: Issues AppendEntries RPCs:
|
||
- Replicate its log
|
||
- Heartbeats to maintain leadership
|
||
|
||
-->
|
||
|
||
<!-- Laurent -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Mandats
|
||
|
||
</header>
|
||
|
||
|
||
|
||
<!--
|
||
|
||
- At most 1 leader per term
|
||
- Some terms have no leader (failed election, example: 3 servers, all switch to candidate at same time, no majority)
|
||
- Each server maintains current term value (no global view)
|
||
- Exchanged in every RPC
|
||
- Peer has later term? Update term, revert to follower
|
||
- Incoming RPC has obsolete term? Reply with error
|
||
|
||
Terms identify obsolete information
|
||
|
||
-->
|
||
|
||
<!-- Clément -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Élection du leader
|
||
|
||
</header>
|
||
|
||

|
||
|
||
<!--
|
||
|
||
RPC = Remote Procedure Call
|
||
|
||
- Server starts as follower
|
||
- Remain follower as long as it receive valid RPC from leader or candidate
|
||
- Leader send periodicaly a heartbeat to retain its authority
|
||
- When a follower does not receive any RPC for a period of time called "timeout election", it starts a new election and become a candidate
|
||
|
||
- Chaque serveur vote un fois en First Come First Served (avec une petite restriction)
|
||
|
||
-->
|
||
|
||
<!-- Clément -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Correction des élections
|
||
|
||
</header>
|
||
|
||
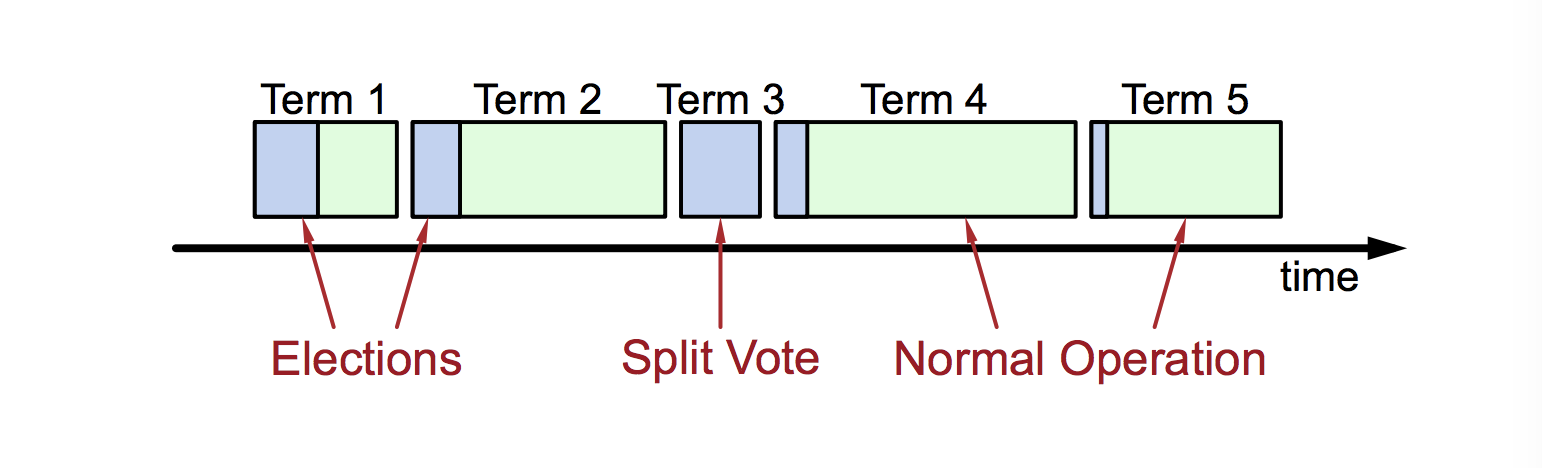
- Sûreté: autoriser au maximum un gagnant par mandat
|
||
- Chaque serveur ne donne qu'un seul vote par mandat (persistant sur disque)
|
||
- Majorité requise pour gagner l'élection
|
||

|
||
- Vivacité: un candidat doit finir par gagner
|
||
- Délais d'expiration des élections aléatoire dans $[T, 2T]$ (e.g. 150-300 ms)
|
||
- Le serveur gagne l'élection en dépassant le délai d'attente avant les autres
|
||
- Fonctionne bien si $T_{\text{diffusion}} \ll T \ll \text{MTBF}$
|
||
- Approche aléatoire plus simple que les autres comme le ranking
|
||
|
||
<!-- Clément -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Structure des journaux
|
||
|
||
</header>
|
||
|
||

|
||
|
||
<!--
|
||
|
||
- Must survive crashes (store on disk)
|
||
- Entry committed if safe to execute in state machines
|
||
- Replicated on majority of servers by leader of its term (that the goal of the leader)
|
||
|
||
-->
|
||
|
||
<!-- Laurent -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Incohérences des journaux
|
||
|
||
</header>
|
||
|
||

|
||
|
||
<!--
|
||
|
||
Logs may be inconsistent after leader change
|
||
- No special steps by new leader:
|
||
- Start normal operation
|
||
- Followers’ logs will eventually match leader
|
||
- Leader’s log is “the truth”
|
||
|
||
Crashes can result in log inconsistencies:
|
||
- Raft minimizes special code for repairing inconsistencies:
|
||
- Leader assumes its log is correct (se pose pas de question sur la validité des ses propres logs, source de vérité)
|
||
- Normal operation will repair all inconsistencies
|
||
|
||
-->
|
||
|
||
<!-- Clément -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Propriété de correspondance des journaux
|
||
|
||
</header>
|
||
|
||

|
||
|
||
<!--
|
||
|
||
Goal: high level of consistency between logs
|
||
|
||
- If log entries on different servers have same index and term:
|
||
- They store the same command
|
||
- The logs are identical in all preceding entries
|
||
- If a given entry is committed, all preceding entries are also committed
|
||
|
||
-->
|
||
|
||
<!-- Laurent -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Réparation des journaux par correspondance
|
||
|
||
</header>
|
||
|
||

|
||
|
||
<!--
|
||
|
||
AppendEntries RPCs include <index, term> of entry preceding new one(s)
|
||
- Follower must contain matching entry; otherwise it rejects request
|
||
- Leader retries with lower log index
|
||
- Implements an induction step, ensures Log Matching Property
|
||
|
||
-->
|
||
|
||
<!-- Clément -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Démo interactive
|
||
|
||
</header>
|
||
|
||
<iframe
|
||
src="https://raft.github.io/raftscope/index.html"
|
||
frameborder="0"
|
||
scrolling="no"
|
||
height=100%
|
||
width=100%
|
||
></iframe>
|
||
|
||
<!--
|
||
|
||
Normal Operation:
|
||
|
||
- Client sends command to leader
|
||
- Leader appends command to its log
|
||
- Leader sends AppendEntries RPCs to all followers
|
||
- Once new entry committed:
|
||
- Leader executes command in its state machine, returns result to client
|
||
- Leader notifies followers of committed entries in subsequent AppendEntries RPCs
|
||
- Followers execute committed commands in their state machines
|
||
- Crashed/slow followers?
|
||
-Leader retries AppendEntries RPCs until they succeed
|
||
- Optimal performance in common case:
|
||
- One successful RPC to any majority of servers
|
||
|
||
-->
|
||
|
||
<!-- Laurent & Clément -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Changement de composition du cluster
|
||
|
||
</header>
|
||
|
||

|
||
|
||
<!--
|
||
|
||
- Dashed lines show configuration entries that have been created but not committed,
|
||
- solid lines show the latest committed configuration entry.
|
||
- The leader first creates the Cold,new configuration entry in its log and commits it to Cold,new (a majority of Cold and a majority of Cnew).
|
||
- Then it creates the Cnew entry and commits it to a majority of Cnew.
|
||
- There is no point in time in which Cold and Cnew can both make decisions independently.
|
||
|
||
-->
|
||
|
||
<!-- Clément -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# De nombreuses implémentations
|
||
|
||
</header>
|
||
|
||
| Name | Primary Authors | Language | License |
|
||
| :------------- | :------------------------------------------------ | :--------- | :--------- |
|
||
| etcd/raft | Blake Mizerany, Xiang Li and Yicheng Qin (CoreOS) | Go | Apache 2.0 |
|
||
| go-raft | Ben Johnson (Sky) and Xiang Li (CMU, CoreOS) | Go | MIT |
|
||
| hashicorp/raft | Armon Dadgar (hashicorp) | Go | MPL-2.0 |
|
||
| copycat | Jordan Halterman | Java | Apache2 |
|
||
| LogCabin | Diego Ongaro (Stanford, Scale Computing) | C++ | ISC |
|
||
| kanaka/raft.js | Joel Martin | Javascript | MPL-2.0 |
|
||
|
||
<!-- Laurent -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Quel degré de hasard est nécessaire pour éviter les votes non concluants ?
|
||
|
||
</header>
|
||
|
||

|
||
|
||
|
||
<!--
|
||
|
||
- a small amount of randomization in the election timeout is enough to avoid split votes in elections.
|
||
- In the absence of randomness, leader election consistently took longer than 10 seconds in our tests due to many split votes. Adding just 5ms of randomness helps significantly, resulting in a median downtime of 287ms.
|
||
- Using more randomness improves worst-case behavior: with 50ms of randomness the worstcase completion time (over 1000 trials) was 513ms.
|
||
|
||
-->
|
||
<!-- Clément -->
|
||
|
||
---
|
||
|
||
<header>
|
||
|
||
# Étude: Raft est-il plus simple que Paxos ?
|
||
|
||
</header>
|
||
|
||
<!--
|
||
|
||
- 43 students in 2 graduate OS classes (Berkeley and Stanford)
|
||
- Group 1: Raft video, Raft quiz, then Paxos video, Paxos quiz
|
||
- Group 2: Paxos video, Paxos quiz, then Raft video, Raft quiz
|
||
- Instructional videos:
|
||
- Same instructor (Ousterhout)
|
||
- Covered same functionality: consensus, replicated log, cluster reconfiguration
|
||
- Fleshed out missing pieces for Paxos
|
||
- Videos available on YouTube
|
||
- Quizzes:
|
||
- Questions in 3 general categories
|
||
- Same weightings for both tests
|
||
- Experiment favored Paxos slightly:
|
||
- 15 students had prior experience with Paxos
|
||
|
||
-->
|
||
|
||

|
||

|
||
|
||
<!-- Laurent -->
|